
1. Giới thiệu
Trong phần này mình sẽ hướng dẫn các bạn đi tìm hiểu về một hệ thống message queue rất hay đó là Kafka mà mình đã tìm hiểu, ứng dụng và làm việc trong thời gian qua.
Ngoài ra mình sẽ hướng dẫn các bạn cách cài đặt Apache Kafka, Apache Zookeeper trên windows để thực hành code. Giải thích ý nghĩa về cách cấu hình Kafka vào một dự án Spring Boot, demo sản phẩm.
Kafka là một hệ thống message theo cơ chế Pub-Sub. Nó cho phép các nhà sản xuất (gọi là producer) viết các message vào Kafka mà một, hoặc nhiều người tiêu dùng (gọi là consumer) có thể đọc, xử lý được những message đó.
2. Cơ chế?
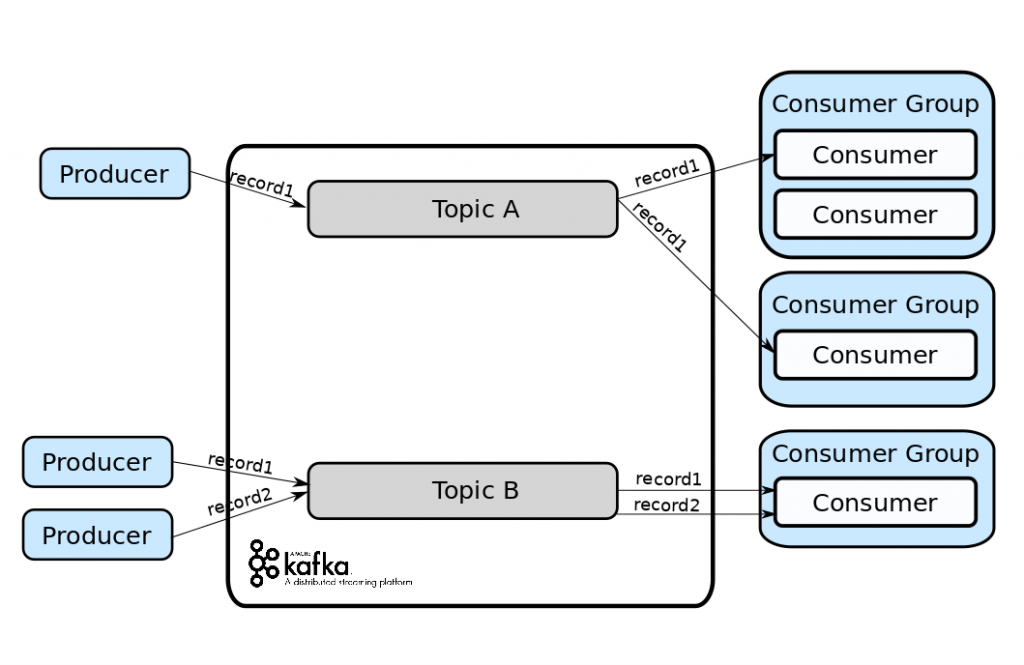
Các message được gửi tới Kafka theo Topic, các Topic giống như là các kênh lưu trữ message từ Producer gửi đến Kafka. Người tiêu dùng (Consumer) đăng kí một hoặc nhiều Topic để tiêu thụ những message đó.
Kafka có thời gian lưu giữ, vì vậy nó sẽ lưu trữ message của bạn theo thời gian hoặc kích thước bạn cấu hình và có thể được chỉ định gửi theo Topic.
Những người tiêu dùng (Consumer) sẽ được gán nhãn theo Consumer Group (nhóm người tiêu dùng), như kiểu một lớp học chia ra 4 tổ, thì mỗi tổ gọi là 1 Consumer Group. Trong một nhóm người tiêu dùng, một hoặc nhiều người tiêu dùng làm việc cùng nhau để xử lý một Topic. Khi có một message mới đến Topic, nó sẽ được gửi đến một Consumer trong một nhóm Consumer Group.
Hiểu đơn giản như việc chúng ta có một tài khoản youtube (consumer) và chúng ta dùng nó thực hiện subscriber nhiều kênh youtube khác nhau (các kênh đó gọi là producer). Thì khi các kênh youtube đó sản xuất nội dung và xuất bản video(publish) thì những consumer đăng kí những kênh đó sẽ ngay lập tức nhận được các thông báo (message) cho chúng ta biết về việc có video mới.
3. Tại sao lại sử dụng Kafka?
Kafka thường được sử dụng trong các kiến trúc dữ liệu phát trực tuyến thời gian thực (real time) để cung cấp các phân tích thời gian thực. Vì Kafka là một hệ thống nhắn tin Pub – Sub nhanh, có thể mở rộng, bền và có khả năng chịu lỗi cao, nên nó được sử dụng trong những trường hợp xử lý khối lượng lớn dữ liệu đến và đáp ứng được khả năng phản hồi ngay lập tức. Kafka có các đặc tính thông lượng, độ tin cậy và sao chép cao hơn, có thể áp dụng cho những thứ như theo dõi các cuộc gọi dịch vụ (theo dõi mọi cuộc gọi).
“Vậy thì câu hỏi đặt ra là tại sao lại sử dụng Kafka mà không phải là một hệ thống Message Queue khác?”
Lý do đơn giản là Kafka có hiệu suất nhanh chóng và ổn định, cung cấp độ bền đáng tin cậy, có đăng kí/ xuất bản linh hoạt phù hợp với số lượng Consumer Group của người tiêu dùng. Có sự sao chép mạnh mẽ, cung cấp cho các Producer sự đảm bảo tính nhất quán. Ngoài ra, Kafka hoạt động tốt với các hệ thống có luồng dữ liệu để xử lý và cho phép các hệ thống đó tổng hợp, chuyển đổi & tải vào các store khác.
4. Tại sao Kafka lại nhanh đến như vậy?
Kafka phụ thuộc rất nhiều vào nhân hệ điều hành để di chuyển dữ liệu một cách nhanh chóng. Nó dựa vào các nguyên tắc của Zero Copy . Kafka cho phép chúng ta sắp xếp các bản ghi dữ liệu thành các khối. Các khối dữ liệu này có thể được nhìn thấy từ đầu đến cuối từ Producer đến hệ thống tệp (Kafka Topic Log) cho Consumer. Batching cho phép nén dữ liệu hiệu quả hơn và giảm độ trễ I / O. Kafka tránh sao chép bộ đệm trong bộ nhớ và truyền dữ liệu vào nhật ký bất biến(offset) thay vì sử dụng truy cập ngẫu nhiên, chính điều này làm cho kafka nhanh đến vậy.
5. Cấu trúc
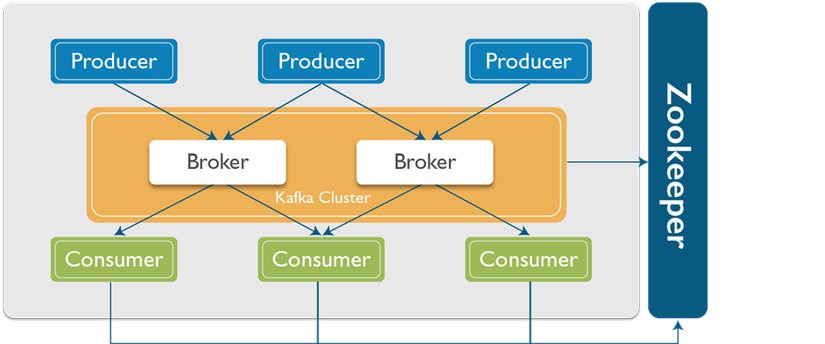
- mô hình cấu trúc kafka đơn giản
- mô hình cấu trúc kafka chi tiết
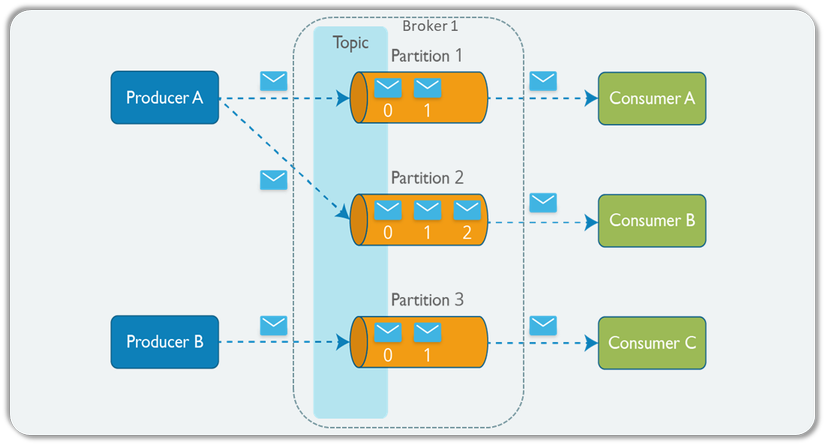
Mô hình cấu trúc Kafka bao gồm các thành phần sau:
Message: Thông tin được gửi đi, có thể là text, binary, Json hoặc một định dạng format nào đó.
Broker: Một host có thể chạy nhiều server kafka, mỗi server như vậy gọi là một broker. Các broker này cùng trỏ tới chung 1 zookeeper, gọi là cụm broker(hay là Clusters). Broker là nơi chứa các partition. Một broker có thể chứa nhiều partition.
Topic: Là nơi chứa các message được publish từ Producer tới Kafka. Nhìn về mặt database thì topic giống như một table trong cơ sở dữ liệu quan hệ, và mỗi message như một bản ghi của table đó.
Partition: Nơi lưu trữ message của topic. Một topic có thể có nhiều partition. Khi khởi tạo topic cần set số partition cho topic đó. Partition càng nhiều thì khả năng làm việc song song cho đọc và ghi được thực hiện nhanh hơn. Các message trong partition được lưu theo thứ tự bất biến(offset). Một partition sẽ có tối thiểu 1 replica để đề phòng trường hợp bị lỗi. Số lượng replica luôn nhỏ hơn số lượng broker.
Producer: Chương trình/service tạo ra message, đẩy message publish vào Topic.
Consumer: Chương trình/service có chức năng subscribe vào một Topic để tiêu thụ, xử lý các message đó.
Một chương trình/service có thể vừa là Producer, vừa là Consumer
Bài hôm nay mình sẽ dừng lại tại đây, ở phần tiếp theo mình sẽ hướng dẫn các bạn cách cài đặt Apache Zookeeper và Apache Kafka trên windows để thực hiện code.
Một số bài viết liên quan:
- Series interview kĩ sư phần mềm
- Series learn Hazelcast
- Series learn Java
- Series crack Intellij IDEA
- Series learn Docker
- Series learn Git
- Series learn Kafka
- Series learn ElasticSearch
- Series learn System Design
- Series learn Microservices
- Series learn Design Pattern
- Series learn Web Service
- Series learn Linux
- Series learn MySQL
- Series learn Soft Skill
- Series learn Testing
- Series review Sách