
Cassandra là một hệ quản trị cơ sở dữ liệu phân tán mã nguồn mở được phát triển bởi Facebook , sau đó chuyển giao cho Apache. Nó được thiết kế để xử lý các lượng dữ liệu lớn và cung cấp khả năng mở rộng linh hoạt và độ tin cậy cao. Cassandra là một giải pháp tốt cho các ứng dụng web có khả năng mở rộng cao và yêu cầu thời gian phản hồi nhanh.
Trong bài viết này, chúng ta sẽ tìm hiểu thêm về Cassandra và tại sao nó là một giải pháp tốt cho các ứng dụng web có khả năng mở rộng cao.
Mục Lục
Kiến trúc của Cassandra
Cassandra được thiết kế dựa trên mô hình hệ thống phân tán (distributed system), trong đó dữ liệu được phân tán trên nhiều nút (node) trên một mạng lưới (cluster). Cassandra sử dụng mô hình peer-to-peer, nghĩa là các node trong cluster hoàn toàn đồng bộ với nhau và có thể giao tiếp trực tiếp với nhau. Điều này giúp tăng tính sẵn sàng và độ tin cậy của hệ thống, tăng khả năng chịu tải của hệ thống và giảm thời gian phản hồi của các truy vấn.
Cassandra sử dụng một số thành phần chính sau:
- Node: là một máy tính trong cluster Cassandra. Mỗi node có thể giữ một phần của dữ liệu và làm việc với các node khác để đồng bộ hóa dữ liệu.
- Data Center: là một nhóm các node nằm trong cùng một vùng địa lý. Data center giúp tăng tính sẵn sàng và độ tin cậy của hệ thống bằng cách giảm độ trễ truyền thông giữa các node trong cùng một data center.
- Cluster: là một nhóm các node và data center.
- Commit Log: là một file log sử dụng để lưu trữ các thay đổi dữ liệu trước khi chúng được lưu trữ vào bộ nhớ đệm.
- Memtable: là một bộ đệm được sử dụng để lưu trữ các thay đổi dữ liệu trước khi chúng được lưu trữ vào disk. Memtable được định dạng dưới dạng bảng.
- SSTable: là một tập hợp các file được sử dụng để lưu trữ dữ liệu trên disk. Mỗi SSTable chứa một phần của dữ liệu và được sắp xếp theo thứ tự khóa chính.
Những tính năng chính của Cassandra
- Khả năng mở rộng linh hoạt: Cassandra có khả năng mở rộng tuyến tính, tức là nó có thể mở rộng bằng cách thêm nút mới vào hệ thống, giúp xử lý được các lượng dữ liệu lớn và yêu cầu tính toán cao.
- Khả năng đáp ứng cao: Cassandra có khả năng đáp ứng cao với các truy vấn phức tạp, đảm bảo thời gian phản hồi nhanh.
- Độ tin cậy cao: Cassandra có khả năng tự động sao lưu và phục hồi dữ liệu, đồng bộ hóa dữ liệu trên các node và cơ chế đảm bảo tính nhất quán của dữ liệu.
- Hỗ trợ cho các ứng dụng đa khu vực: Cassandra có khả năng hoạt động hiệu quả trong các môi trường phân tán đa khu vực, với khả năng đồng bộ hóa và sao lưu dữ liệu giữa các khu vực.
- Tính linh hoạt và đa dạng: Cassandra có thể lưu trữ các dữ liệu phức tạp và có cấu trúc, bao gồm các loại dữ liệu như JSON, XML và các kiểu dữ liệu khác.
Các ứng dụng của Cassandra
Cassandra được sử dụng rộng rãi trong nhiều lĩnh vực, bao gồm các ứng dụng web, mạng xã hội, hệ thống IoT, lĩnh vực tài chính và nhiều lĩnh vực khác. Dưới đây là một số ứng dụng trong thực tế của Cassandra:
- Web Application: Cassandra được sử dụng rộng rãi trong các ứng dụng web, đặc biệt là các ứng dụng với lượng dữ liệu lớn và yêu cầu tính mở rộng cao.
- Mạng xã hội: Cassandra được sử dụng trong các mạng xã hội để lưu trữ các thông tin về người dùng và các tương tác giữa người dùng.
- Hệ thống IoT: Cassandra được sử dụng để lưu trữ các dữ liệu liên quan đến các thiết bị IoT, như các cảm biến và thiết bị giám sát.
- Lĩnh vực tài chính: Cassandra được sử dụng để lưu trữ các thông tin về giao dịch tài chính và các hoạt động khác trong lĩnh vực tài chính.
- Lĩnh vực y tế: Cassandra được sử dụng để lưu trữ các thông tin về bệnh nhân, lịch sử bệnh án và các dữ liệu y tế khác.
Write Consitency trong Cassandra
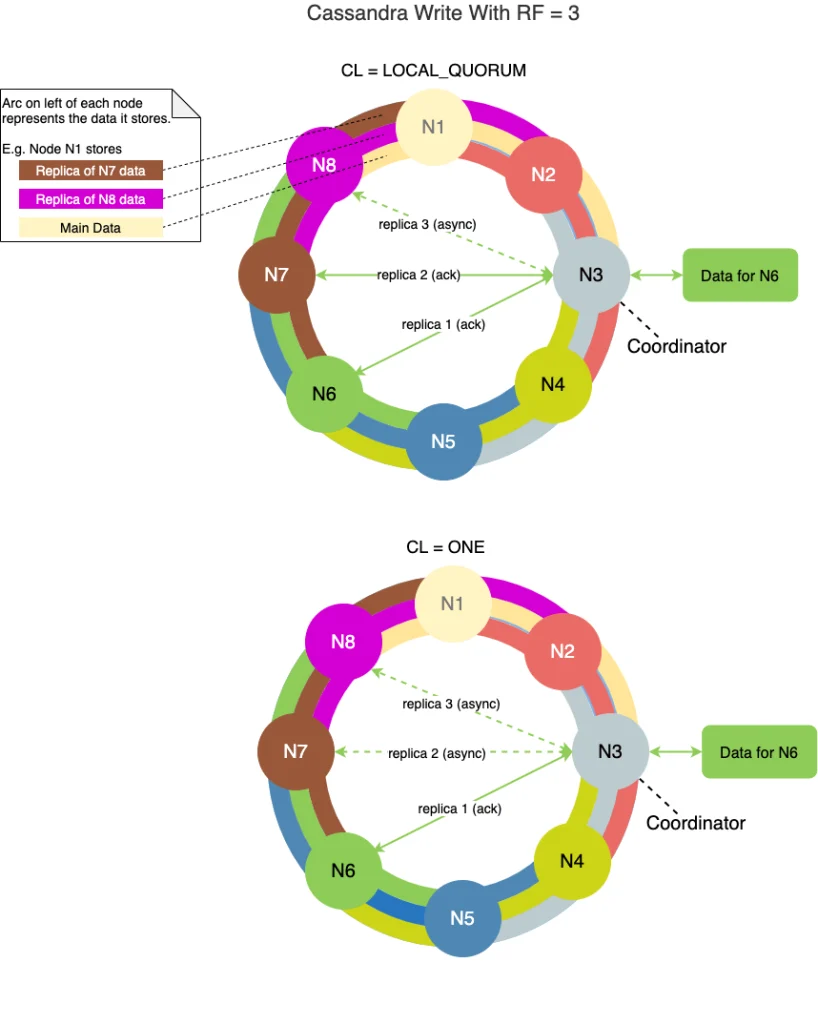
Trong Cassandra, Write Consistency được quản lý thông qua một cơ chế ghi nhận(acknowledgment mechanism) giữa các node. Cơ chế này đảm bảo rằng dữ liệu đã được ghi đến đúng số lượng replica nhất định trước khi trả về cho client.
Khi một client gửi một yêu cầu ghi dữ liệu đến Cassandra, nó được gửi đến một node coordinator đầu tiên (gọi là node điều phối viên). Node coordinator sẽ đảm bảo rằng dữ liệu được ghi đến đúng số lượng replica đã được xác định bởi tham số Consistency Level.
Consistency Level là một tham số được sử dụng để định nghĩa số lượng replica cần phải được ghi đến trước khi trả về kết quả cho client. Cassandra hỗ trợ một số Consistency Level khác nhau như ONE, TWO, QUORUM, LOCAL_QUORUM, EACH_QUORUM, ALL, ANY.
Ví dụ, nếu Consistency Level được đặt là ONE, có nghĩa là chỉ cần một replica được ghi thành công thì kết quả sẽ được trả về cho client. Tuy nhiên, nếu Consistency Level được đặt là QUORUM, có nghĩa là phải ghi đến ít nhất số lượng replica bằng một phần hai số lượng replica có trong cluster (số lượng replica được đặt trước đó), trước khi kết quả được trả về cho client.
Sau khi đủ số lượng replica được ghi thành công, Cassandra sẽ trả về cho client một acknowledgement để xác nhận rằng dữ liệu đã được ghi thành công. Nếu không đạt được số lượng replica được yêu cầu, Cassandra sẽ trả về một lỗi (error) cho client.
Quá trình này đảm bảo rằng dữ liệu được ghi vào Cassandra theo đúng Consistency Level đã được xác định trước đó, đồng thời giúp đảm bảo tính nhất quán và độ tin cậy của dữ liệu.
Read Consitency trong Cassandra
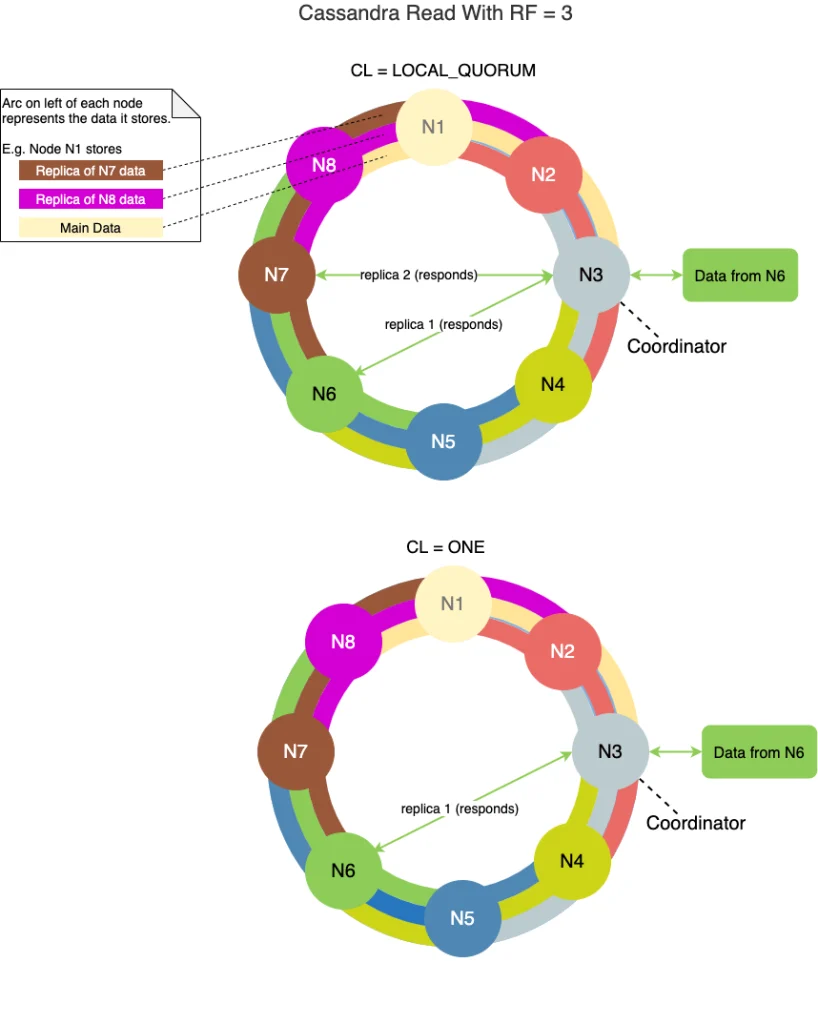
Tương tự như Write Consistency, Read Consistency trong Cassandra cũng được quản lý thông qua cơ chế đồng bộ giữa các replica node.
Khi một yêu cầu đọc dữ liệu được gửi đến một node coordinator, node này sẽ kiểm tra các replica node để lấy dữ liệu. Consistency Level được sử dụng để xác định số lượng replica node cần được truy vấn để trả về kết quả đọc dữ liệu.
Nếu Consistency Level được đặt là ONE, nghĩa là chỉ cần một replica node có thể trả về kết quả, thì node coordinator sẽ chỉ truy vấn một replica node gần nhất để lấy dữ liệu. Tuy nhiên, nếu Consistency Level được đặt là QUORUM, nghĩa là phải đọc từ 50% replica node hoặc phần lớn replica node, thì node coordinator sẽ truy vấn số lượng tới số lượng node tương ứng và trả về kết quả
Trong trường hợp đọc dữ liệu với Consistency Level QUORUM, nếu một hoặc nhiều replica node không trả về kết quả trong thời gian quy định, Cassandra sẽ trả về một lỗi (error) cho client, đảm bảo tính nhất quán và độ tin cậy của dữ liệu.
Việc sử dụng Read Consistency trong Cassandra đảm bảo rằng dữ liệu được trả về cho client là nhất quán và đáng tin cậy, và giúp đảm bảo rằng tất cả các replica node có dữ liệu được truy vấn đồng thời, từ đó cải thiện hiệu suất hệ thống.
Cassandra được sử dụng để đáp ứng việc gì?
Cassandra được thiết kế để phục vụ cả các ứng dụng đọc nhiều và ghi nhiều. Tuy nhiên, hệ thống này được tối ưu để hỗ trợ ứng dụng đọc nhiều với tốc độ truy vấn cực nhanh và khả năng mở rộng linh hoạt.
Điều này được đạt được thông qua cách Cassandra lưu trữ dữ liệu dưới dạng cột (column-oriented storage) thay vì lưu trữ dưới dạng hàng như các hệ thống cơ sở dữ liệu quan hệ truyền thống. Nó cho phép Cassandra truy vấn dữ liệu nhanh hơn vì nó chỉ truy cập vào các cột được yêu cầu trong truy vấn thay vì phải truy cập toàn bộ hàng.
Ngoài ra, Cassandra cũng hỗ trợ việc ghi nhiều với khả năng ghi dữ liệu đồng thời (concurrent writes) và khả năng mở rộng linh hoạt, cho phép ứng dụng có thể mở rộng thêm các node để xử lý lưu trữ dữ liệu nếu cần thiết.
Tuy nhiên, để đạt được tốc độ ghi tối đa, Cassandra thường sử dụng các tùy chọn bảo vệ dữ liệu tối thiểu, chẳng hạn như không đảm bảo tính toàn vẹn của dữ liệu khi ghi. Do đó, Cassandra thường được sử dụng trong các ứng dụng cần tính sẵn sàng cao và chấp nhận một số đánh đổi về tính toàn vẹn dữ liệu khi ghi.
Trong bản cập nhật Cassandra 4.0.0 thì hiệu suất của việc READ tăng lên đáng kể so với phiên bản Cassandra 3.11.11
Bài tiếp theo chúng ta sẽ tìm hiểu chi tiết hơn về cách cài đặt Cassandra, cũng như cách tương tác với cơ sở dữ liệu này.
Một số bài viết nổi bật:
- Crack Intellij IDEA Ultimate version 2022
- How to build Cron Job for multiple instances with ShedLock
- Distributed Lock with Hazelcast and Spring
- How to build Rate Limit with Hazelcast and Spring Boot
- Biết sử dụng git cherry-pick để làm việc hiệu quả hơn
- Git revert với Git reset hoạt động như thế nào?
- Git stash giúp bạn trở nên chuyên nghiệp như thế nào
- Học cách lắng nghe tích cực để hiểu người khác hơn
- Kĩ năng quản lý căng thẳng cho Developer
- Câu chuyện phỏng vấn online mùa Covid
- Series crack Intellij IDEA
- Series tìm hiểu Docker
- Series tìm hiểu Git
- Series tìm hiểu Kafka
- Series tìm hiểu ElasticSearch
- Phỏng vấn dạo kĩ sư phần mềm 2023