Mục Lục
Bài toán tổng hợp số dư cho 1 triệu tài khoản
Trong một hệ thống tài chính, hoặc có thể những hệ thống khác luôn phát sinh bài toán cần chạy job tổng hợp cho một tập dữ liệu nào đó: có thể là quét toàn bảng, tổng hợp dữ liệu, hoặc migrate sang hệ thống đích nào đó, xử lý rất nhiều khâu công việc khác nhau, công việc lặp đi lặp lại ngày qua ngày.
Vấn đề ở đây là khi có những bài toán kiểu như vậy thì làm thế nào chúng ta sẽ xử lý để việc thực thi Job được nhanh nhất, đảm bảo performance hệ thống, không gây quá tải hoặc làm downtime hệ thống chính.
Trong phạm vi bài viết này, mình sẽ chia sẻ cách mình xử lý để chạy job tổng hợp đảm bảo hiệu suất cao.
Bài toán đơn giản như sau, cứ cuối mỗi ngày hệ thống sẽ cần chạy Job tổng hợp số dư cho xx triệu tài khoản.
Số dư cuối ngày của một tài khoản trong một hệ thống tài chính sẽ bao gồm một vài thông số như sau:
- open balance: số dư đầu ngày T (bằng với close balance ngày T-1)
- close balance: số dư cuối ngày
- debit balance: số dư ghi nợ trong ngày
- credit balance: số dư ghi có trong ngày
- debit transaction: số lượng giao dịch ghi nợ
- credit transaction: số lượng giao dịch ghi có
Về cơ bản là sẽ cần tổng hợp lại một số thông số trên theo ngày, cho từng account khác nhau, mỗi ngày sẽ cần tổng hợp dữ liệu và phát sinh xx triệu bản ghi tổng hợp phụ thuộc theo số lượng tài khoản của hệ thống.
Luồng xử lý nghiệp vụ chính
Về quy trình chính mình sẽ biểu diễn như ảnh bên dưới, những phần tối ưu ở phần sau của bài mình sẽ không vẽ lại nữa vì luồng cơ bản thì nó sẽ như nhau thôi.
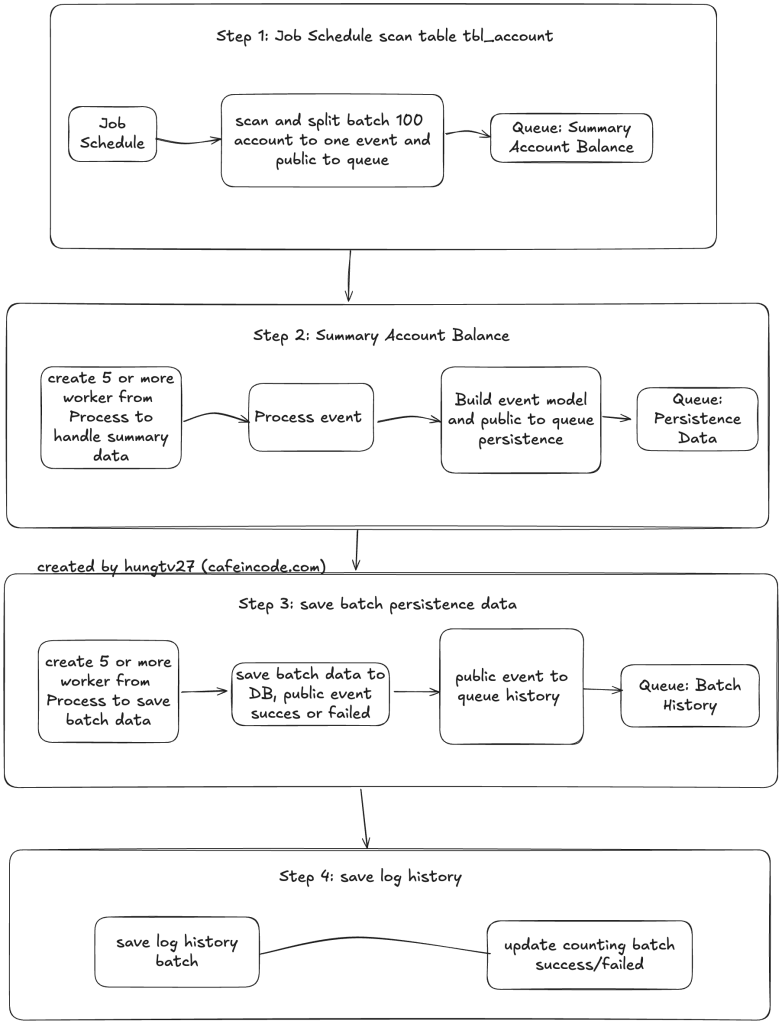
Mình chia làm 4 step chính, mỗi step sẽ làm những nhiệm vụ riêng:
Step 1: scan toàn bộ danh sách tài khoản
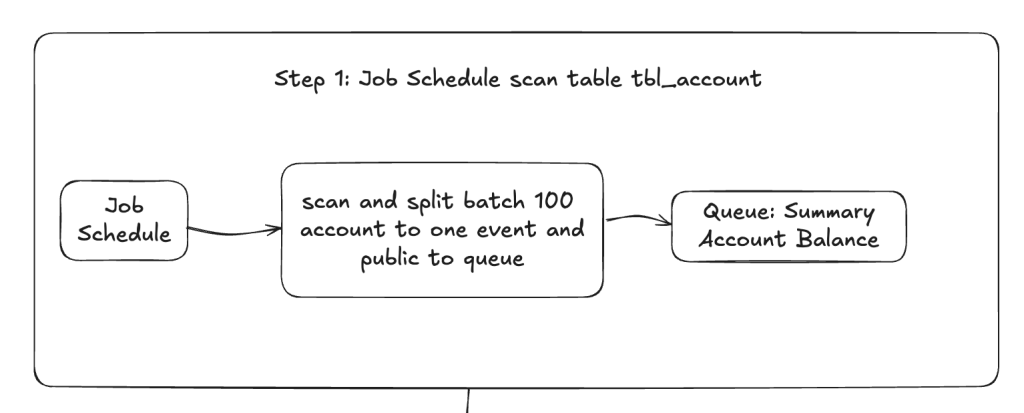
Ở step đầu tiên này, nhiệm vụ chính của nó là quét danh sách tài khoản trong bảng account (phần tối ưu chính sẽ nằm ở bước này)
Sẽ có một Schedule Job quét tuần tự bảng account để lấy ra danh sách tài khoản, quét theo từng page từ đầu cho đến page cuối cùng của bảng.
Trong quá trình quét sẽ gom nhóm mỗi 100 tài khoản thành 1 batch, mỗi batch này là 1 event, bổ sung thêm một số tham số nữa trong event rồi bắn vào queue của Step 2.
Step 2: xử lý logic chính của việc tổng hợp dữ liệu
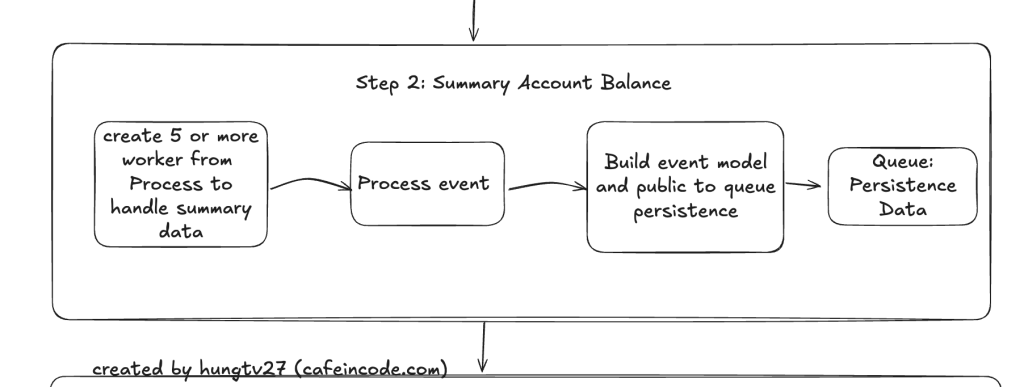
Ở step 2 này, nhiệm vụ chính sẽ là tổng hợp dữ liệu tài khoản theo từng event, vì mỗi event đang là batch 100 tài khoản ở trên, nên việc xử lý trên từng event cũng chính là xử lý trên batch 100 tài khoản cùng lúc, việc này sẽ giúp việc tổng hợp dữ liệu được nhanh hơn so với việc xử lý từng tài khoản.
Sau khi tổng hợp số dư tài khoản xong, sẽ thực hiện build ra một model event mới, bắn sang queue của step 3 để thực hiện lưu dữ liệu xuống database.
Bản chất model event này sẽ là dữ liệu cần phải insert/update vào database của 100 tài khoản sau khi tổng hợp, tuy nhiên ở bước này sẽ không thực hiện insert hay update mà sẽ bắn event sang step 3 để xử lý.
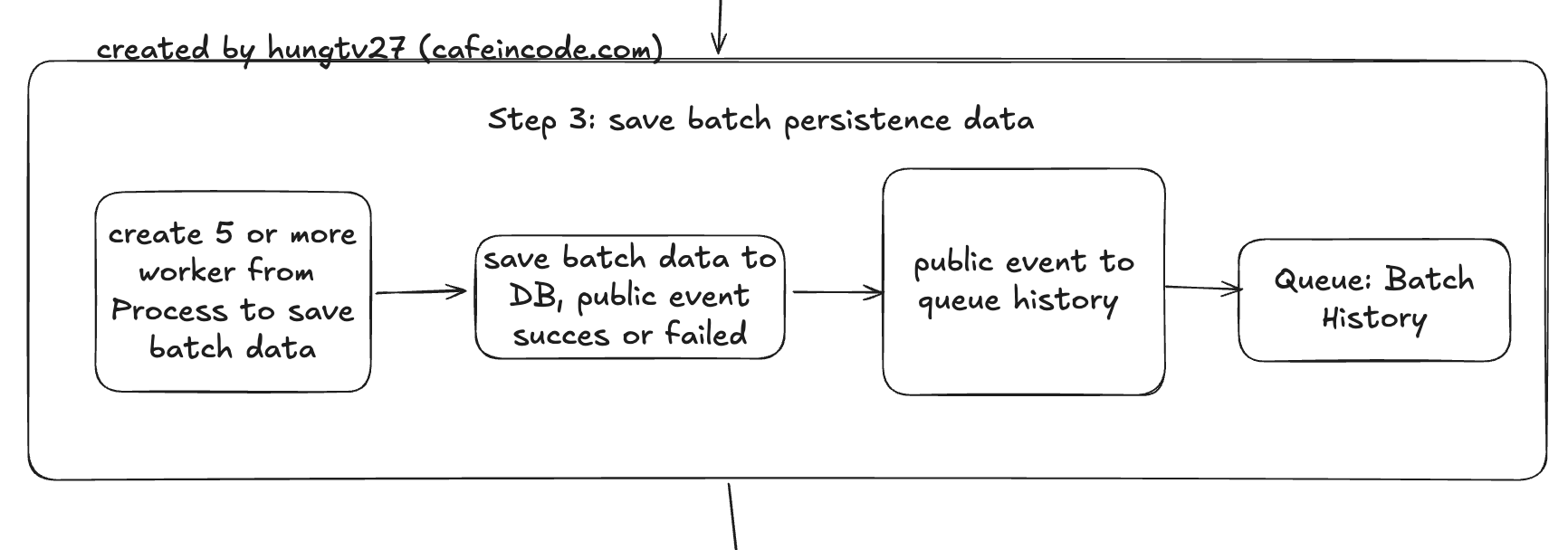
Step 3: xử lý lưu dữ liệu đã được tổng hợp xuống database
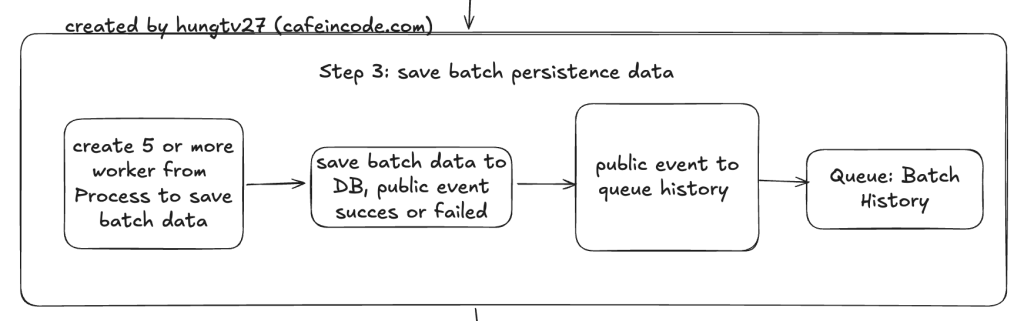
Ở step 3 này, nhiệm vụ chính của nó là lưu dữ liệu xuống database dựa theo model event của step 2, việc lưu batch data này xuống db sẽ có những trường hợp xử lý thành công hoặc lỗi.
Với mỗi trường hợp như vậy thì chúng ta sẽ bắn ra hai loại event khác nhau: SUCCESS hoặc FAILED để step 4 thực hiện xử lý tiếp
Step 4: cập nhật trạng thái xử lý Job
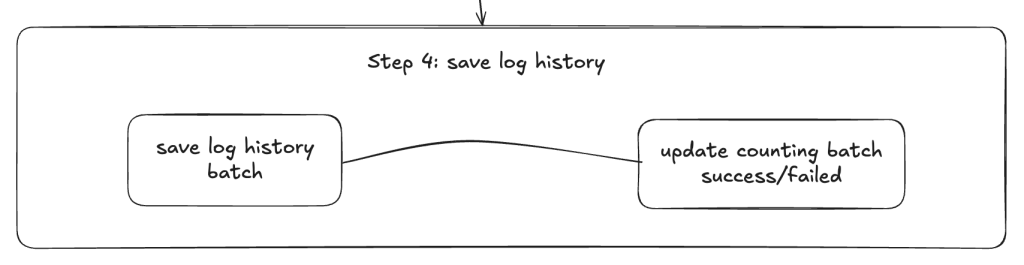
Step 4 này có nhiệm vụ chính là cập nhật biến đếm cho những batch đã xử lý thành công, batch xử lý thất bại, kiểm tra và cập nhật trạng thái hoàn thành của Job.
Các bạn có thể đưa step 3 và 4 gộp làm 1 cũng được, tuy nhiên để tránh việc bị race condition vì ở step 3 là đa luồng nên mình quyết định đưa việc cập nhật trạng thái job này về 1 luồng ở step 4, sẽ luôn đảm bảo việc update số lượng batch con đã xử lý (success, failed) trong một batch cha to là tuần tự.
Hơn nữa, việc tách step 3 và 4 đảm bảo việc phân tách rõ ràng chức năng và bảo trì sau này, hai step không liên quan đến nhau, sau này sửa code luồng step 4 để bổ sung logic hay cập nhật gì đó thì không cần sửa code ở step 3.
Chạy thử trên 1 triệu dữ liệu
Để chuẩn bị cho việc chạy thử dữ liệu trên 1 triệu tài khoản, mình sẽ cần làm hai việc chính sau:
- Fake 1 triệu dữ liệu tài khoản
- Fake dữ liệu Entry, chính là dữ liệu nguồn dùng để tổng hợp
Vì nhiều lý do nên mình xin phép không chia sẻ mã nguồn thực hiện chính trong bài viết này, tuy nhiên flow thực hiện và ý tưởng thì vẫn như mình trình bày từ đầu đến giờ.
Chèn dữ liệu giả cho bảng account
Bảng account của mình hiện tại chỉ có hai trường account_no và accounting_type:
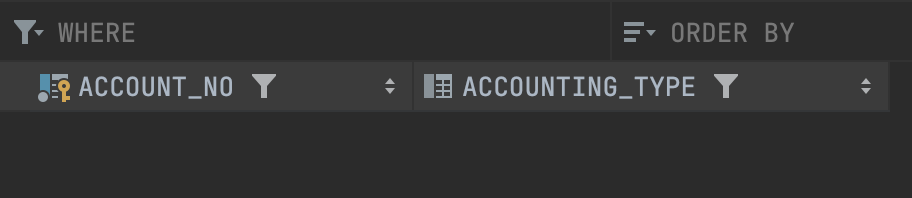
Mình sẽ tạo một package để generate ra dữ liệu giả, mô tả như bên dưới:
CREATE OR REPLACE PACKAGE PKG_ACCOUNT_UTIL AS
PROCEDURE INSERT_FAKE_DATA(p_num_records IN NUMBER);
END PKG_ACCOUNT_UTIL;
CREATE OR REPLACE PACKAGE BODY PKG_ACCOUNT_UTIL AS
PROCEDURE INSERT_FAKE_DATA(p_num_records IN NUMBER) IS
v_account_no VARCHAR2(255);
v_accounting_type VARCHAR2(255);
v_inserted_count NUMBER := 0;
BEGIN
WHILE v_inserted_count < p_num_records LOOP
v_account_no := '08' || TO_CHAR(DBMS_RANDOM.VALUE(1000000000, 9999999999), 'FM9999999990');
v_accounting_type := CASE WHEN DBMS_RANDOM.VALUE(0, 1) < 0.5 THEN 'DR' ELSE 'CR' END;
BEGIN
INSERT INTO ACCOUNT (ACCOUNT_NO, ACCOUNTING_TYPE)
VALUES (v_account_no, v_accounting_type);
v_inserted_count := v_inserted_count + 1;
EXCEPTION
WHEN DUP_VAL_ON_INDEX THEN
NULL;
END;
END LOOP;
COMMIT;
END INSERT_FAKE_DATA;
END PKG_ACCOUNT_UTIL;Sau khi tạo xong, sẽ thực hiện chạy insert 1 triệu bản ghi account
BEGIN
PKG_ACCOUNT_UTIL.INSERT_FAKE_DATA(1000000);
END;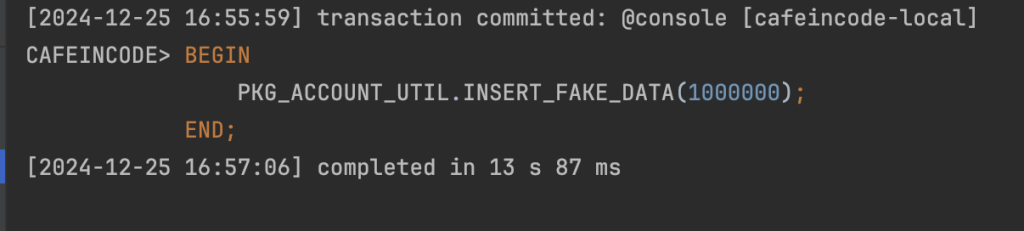
Chạy insert 1 triệu data hết khoảng 13s
Chèn dữ liệu nguồn cho bảng Entry
Bảng Entry sẽ chứa dữ liệu nguồn dùng để tổng hợp data.
CREATE OR REPLACE PACKAGE PKG_ENTRY_UTIL AS
PROCEDURE INSERT_FAKE_ENTRY(p_num_records IN NUMBER);
END PKG_ENTRY_UTIL;
CREATE OR REPLACE PACKAGE BODY PKG_ENTRY_UTIL AS
PROCEDURE INSERT_FAKE_ENTRY(p_num_records IN NUMBER) IS
v_entry_id VARCHAR2(255);
v_transaction_id VARCHAR2(255);
v_account_no VARCHAR2(255);
v_amount NUMBER := 27000;
v_sign VARCHAR2(255);
v_account_category VARCHAR2(255);
v_currency VARCHAR2(20) := 'VND';
v_status VARCHAR2(100) := '1';
v_company_code VARCHAR2(255) := 'CAFEINCODE';
v_created_date TIMESTAMP(6);
v_processing_date TIMESTAMP(6);
v_success_count NUMBER := 0;
v_attempts NUMBER := 0;
TYPE t_account_no_list IS TABLE OF VARCHAR2(255);
v_account_no_list t_account_no_list;
v_account_index NUMBER := 1;
BEGIN
SELECT account_no BULK COLLECT INTO v_account_no_list FROM ACCOUNT;
WHILE v_success_count < p_num_records LOOP
v_attempts := v_attempts + 1;
v_account_no := v_account_no_list(MOD(v_account_index - 1, v_account_no_list.COUNT) + 1);
v_account_index := v_account_index + 1;
v_entry_id := '270519955555555555555.' || v_attempts || '.1';
v_transaction_id := v_entry_id;
v_sign := CASE WHEN DBMS_RANDOM.VALUE(0, 1) < 0.5 THEN 'DR' ELSE 'CR' END;
v_account_category := CASE
WHEN DBMS_RANDOM.VALUE(0, 3) < 1 THEN '01006'
WHEN DBMS_RANDOM.VALUE(0, 3) < 2 THEN '05001'
ELSE '05000'
END;
v_created_date := TO_TIMESTAMP('2024-12-26 09:16:18', 'YYYY-MM-DD HH24:MI:SS');
v_processing_date := TO_DATE('2024-12-25', 'YYYY-MM-DD') + INTERVAL '15' HOUR + INTERVAL '15' MINUTE;
BEGIN
INSERT INTO ENTRY (
ENTRY_ID, TRANSACTION_ID, ACCOUNT_NO, AMOUNT, SIGN, ACCOUNT_CATEGORY, CURRENCY,
STATUS, COMPANY_CODE, CREATED_DATE, PROCESSING_DATE
) VALUES (
v_entry_id, v_transaction_id, v_account_no, v_amount, v_sign, v_account_category, v_currency,
v_status, v_company_code, v_created_date, v_processing_date
);
v_success_count := v_success_count + 1;
EXCEPTION
WHEN DUP_VAL_ON_INDEX THEN
NULL;
END;
END LOOP;
COMMIT;
END INSERT_FAKE_ENTRY;
END PKG_ENTRY_UTIL;
BEGIN
PKG_ENTRY_UTIL.INSERT_FAKE_ENTRY(2000000);
END;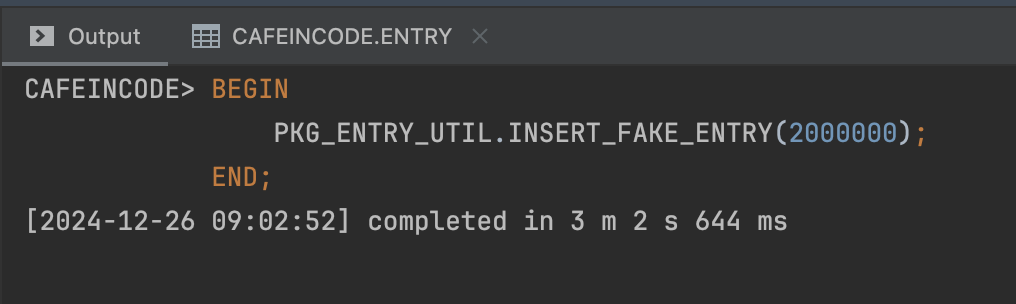
Chạy insert 2 triệu bản ghi dữ liệu entry hết khoảng 3 phút.
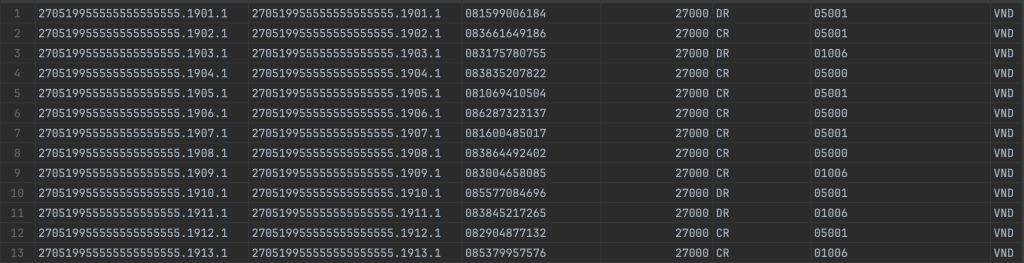
Run project
Giờ chúng ta sẽ run project lên và chạy đo thử việc quét 1 triệu tài khoản hết khoảng thời gian bao lâu
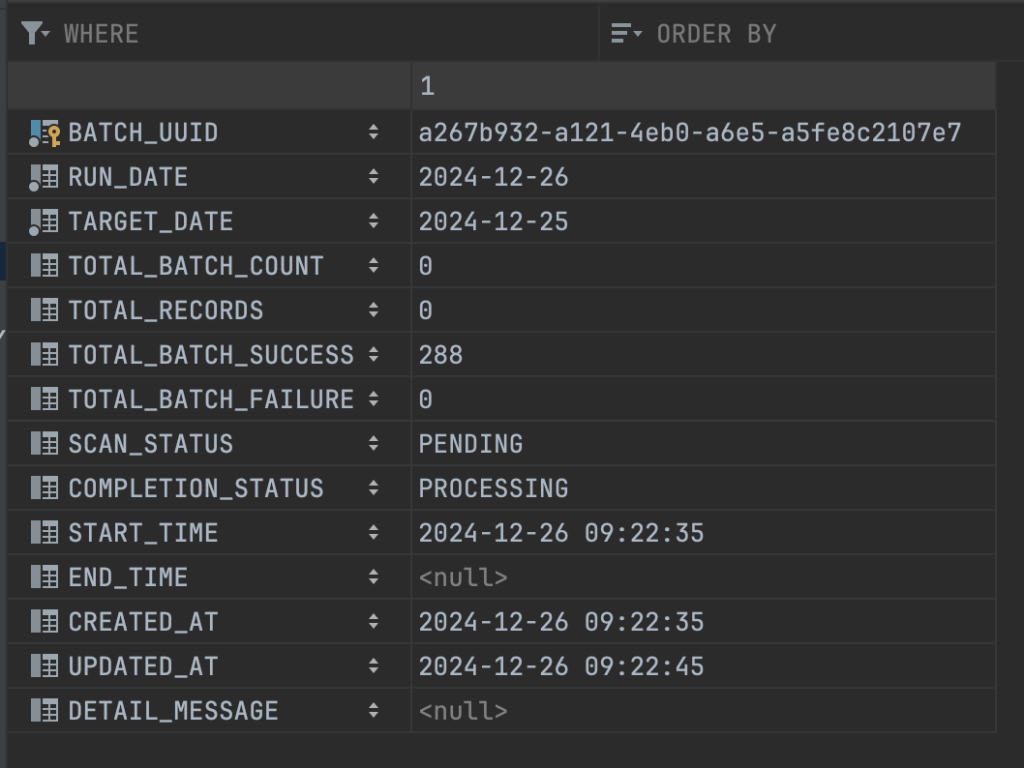
Do việc scan tài khoản đang chỉ chạy trên 1 luồng, nên mình tính sơ sơ với 1.000.000 tài khoản thì sẽ cần phải chạy 10.000 batch, mỗi batch là 100 tài khoản, vậy nên con số total_batch_count sẽ là 10.000 và con số total_batch_success+total_batch_failure = 10.000
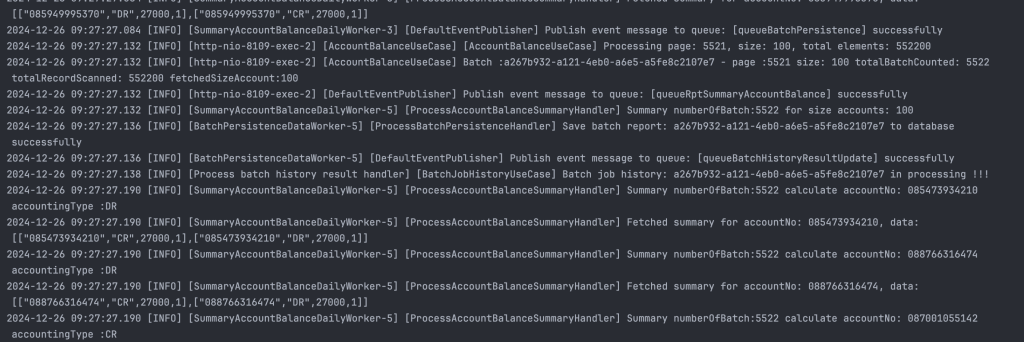
Quá trình tổng hợp tài khoản vẫn đang diễn ra, sau cỡ khoảng 14 phút gì đó thì toàn bộ quá trình quét và tổng hợp dữ liệu cũng kết thúc.

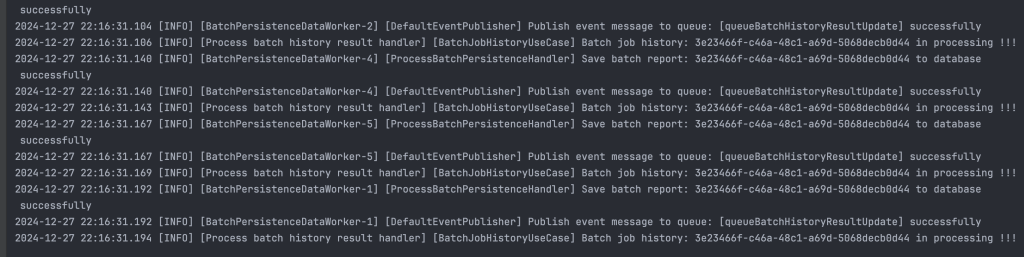
2024-12-26 09:36:44.100 [INFO] [BatchPersistenceDataWorker-2] [ProcessBatchPersistenceHandler] Save batch report: a267b932-a121-4eb0-a6e5-a5fe8c2107e7 to database successfully
2024-12-26 09:36:44.100 [INFO] [BatchPersistenceDataWorker-2] [DefaultEventPublisher] Publish event message to queue: [queueBatchHistoryResultUpdate] successfully
2024-12-26 09:36:44.101 [INFO] [Process batch history result handler] [BatchJobHistoryUseCase] Batch job history: a267b932-a121-4eb0-a6e5-a5fe8c2107e7 in processing !!!
2024-12-26 09:36:44.131 [INFO] [http-nio-8109-exec-2] [AccountBalanceUseCase] [AccountBalanceUseCase] Processing page: 10000, size: 100, total elements: 0
2024-12-26 09:36:44.446 [INFO] [http-nio-8109-exec-2] [ExecutionTimeMonitorAspect] End service: JobSummaryAccountBalanceDaily execution time: 849357 ms - 849 s Thông tin chi tiết về lịch sử chạy job được lưu ở bảng bên dưới, các bạn có thể thấy job tổng hợp đã xử lý thành công 1.000.000 bản ghi account, 10.000 batch event, số lượng batch xử lý thành công cũng là 10.000
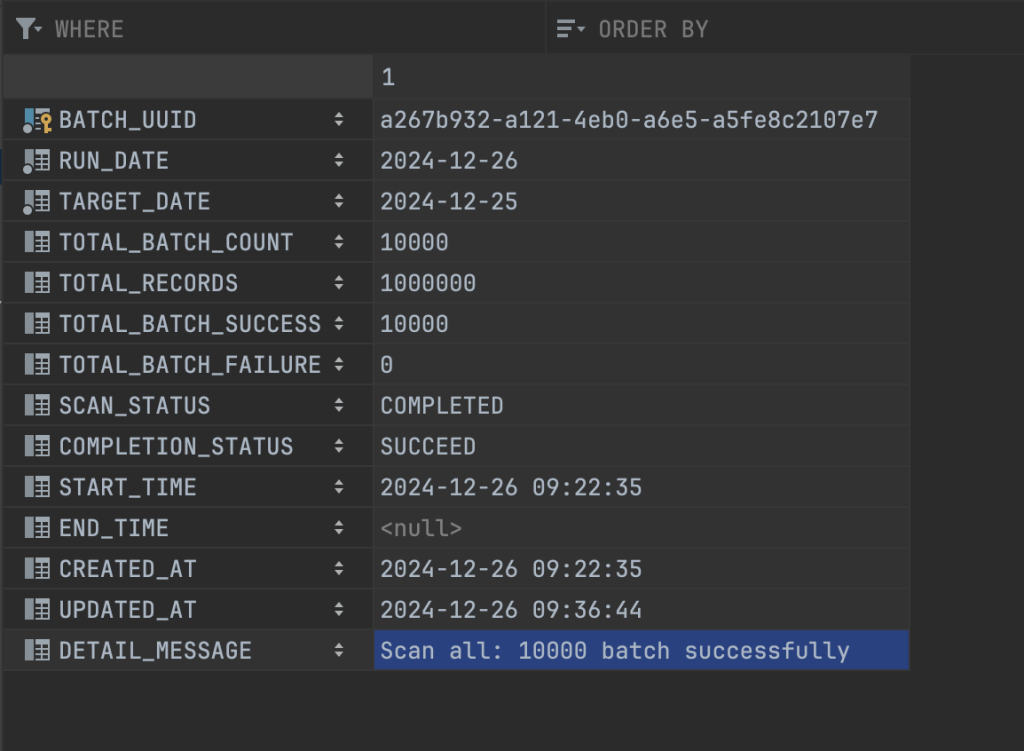
Kết quả dữ liệu tổng hợp được lưu vào một bảng report
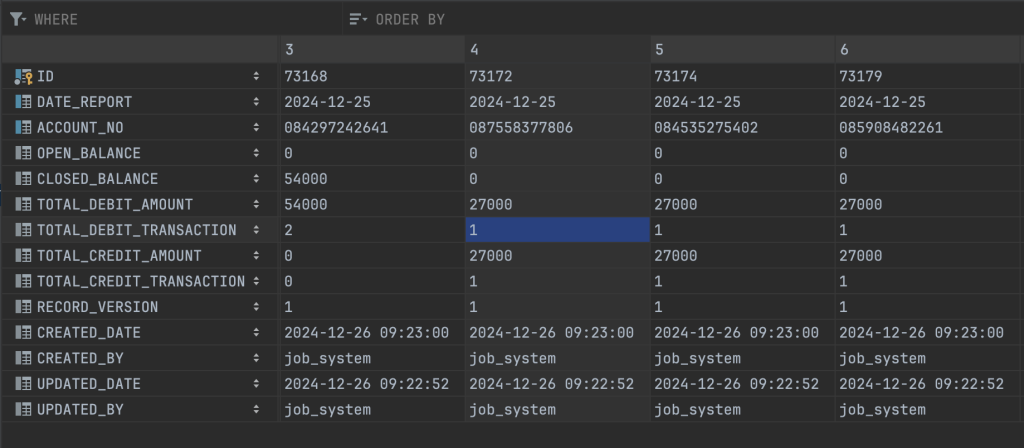
Tuy nhiên có một điều chúng ta cần chú ý ở đây, đó là việc xử lý cho 1.000.000 tài khoản đang mất khoảng 14 phút, theo cá nhân mình đánh giá như thế là khá chậm và sẽ cần cải phải thiện thêm.
Trong toàn bộ luồng xử lý của chúng ta, thì việc chậm nhất đang nằm ở step 1, vì ở step này việc scan tuần tự từng page từng page và chỉ có 1 luồng xử lý nên gần như thời gian xử lý của job bằng với thời gian quét tài khoản.
Cách tiếp cận mới tối ưu thời gian
Thay đổi cách đọc dữ liệu trong bảng account
Giả sử bảng account đã có sẵn và không thể bổ sung thêm cột, vậy nên mình sẽ tạo thêm một view để quét dữ liệu từ cái view đó.
Dưới đây là script để tạo một view mới từ bảng account cũ, được bổ sung thêm một trường partition_id để chia các account về 10 nhóm
CREATE OR REPLACE VIEW account_partitions_view AS
SELECT
account_no,
ACCOUNTING_TYPE,
MOD(ORA_HASH(account_no), 10) + 1 AS partition_id
FROM ACCOUNT;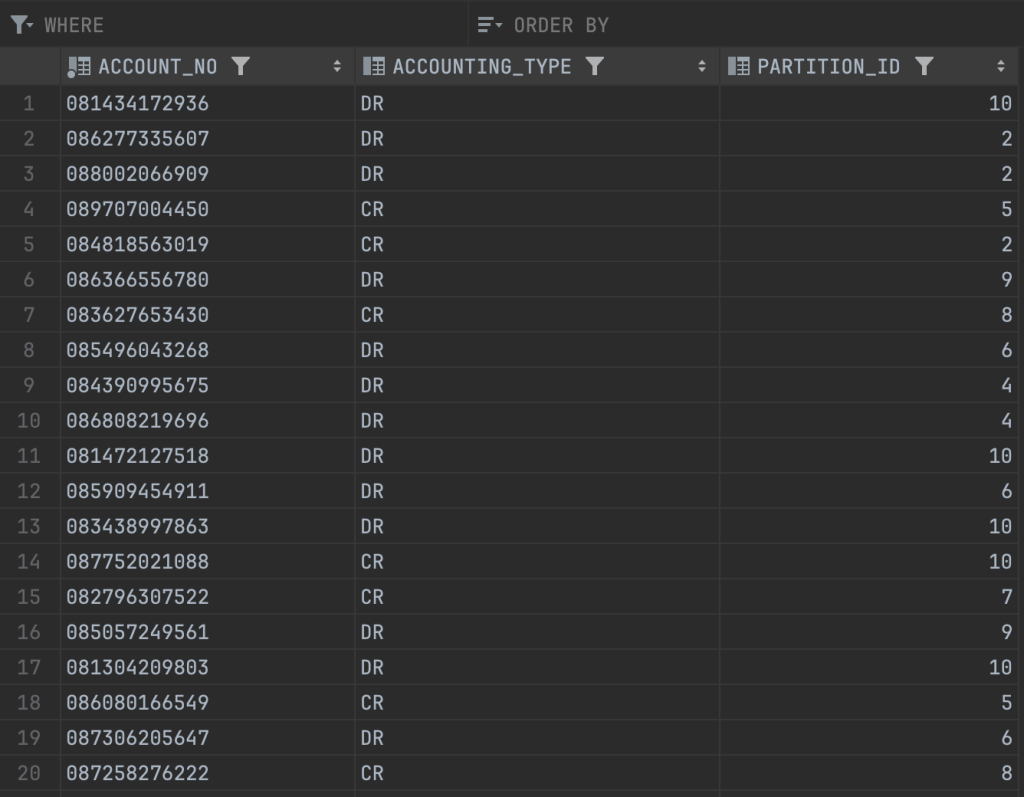
Tới đây là việc phân chia tài khoản ra 10 nhóm đã xong, giờ việc scan tài khoản ở step 1 sẽ không cần phải chạy 1 luồng nữa mà mình sẽ chạy cho 10 luồng để scan account theo từng partition.
Mỗi luồng sẽ thực hiện scan bản ghi theo 1 partition_id nhất định, như vậy việc quét dữ liệu của chúng ta sẽ được tối ưu hơn.
var executorService = Executors.newFixedThreadPool(10);
for (long i = 1; i <= 10; i++) {
long partitionId = i;
executorService.submit(() -> scanAccountByPartitionId(batchJobLog.getBatchUuid(), partitionId, dateTime));
}Sửa lại chút logic và chạy theo hướng như trên, chúng ta sẽ có kết quả sau:
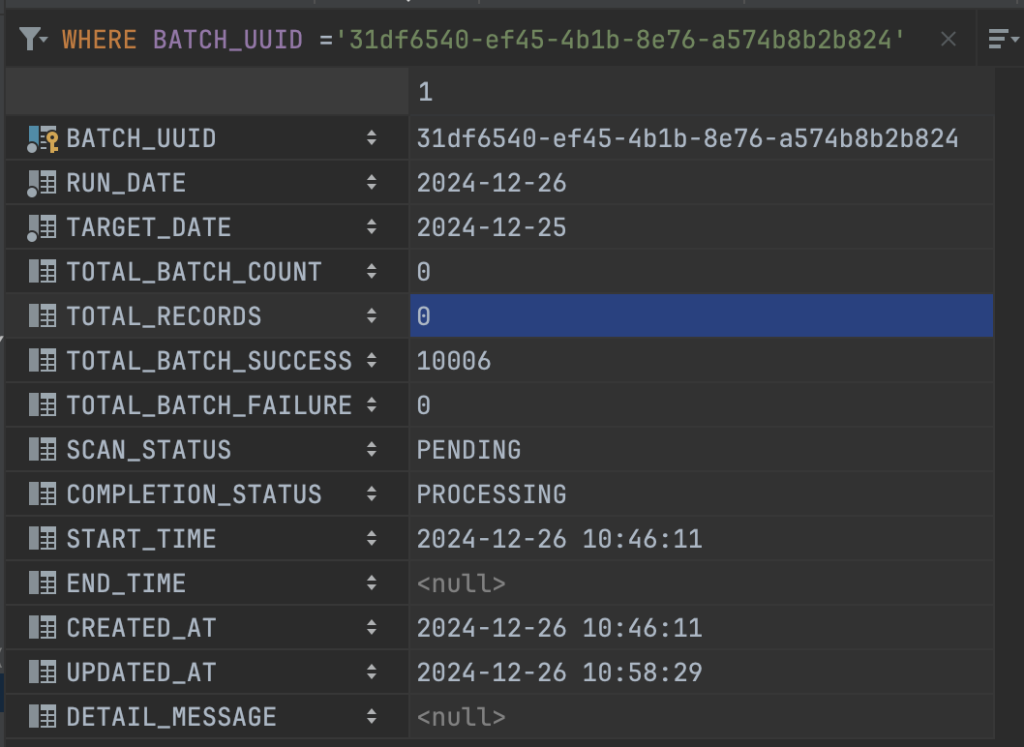
Thời gian thực hiện hết 12 phút, có vẻ như không nhanh hơn được là bao nhiêu, cơ bản là cột partition_id trên view mà chúng ta mới tạo không có index nên việc quét sẽ không được nhanh.
Giờ mình sẽ thay đổi lại một chút về dữ liệu nguồn, trên view cũ kia mình không thể đánh index được nên mình sẽ tạo ra thêm một materialized view mới, và đánh index trên cột partition_id:
CREATE MATERIALIZED VIEW account_partitions_view2
BUILD IMMEDIATE
REFRESH COMPLETE ON DEMAND
AS
SELECT
account_no,
ACCOUNTING_TYPE,
MOD(ORA_HASH(account_no), 10)+1 AS partition_id
FROM ACCOUNT;
CREATE INDEX idx_partition_id ON account_partitions_view2(partition_id);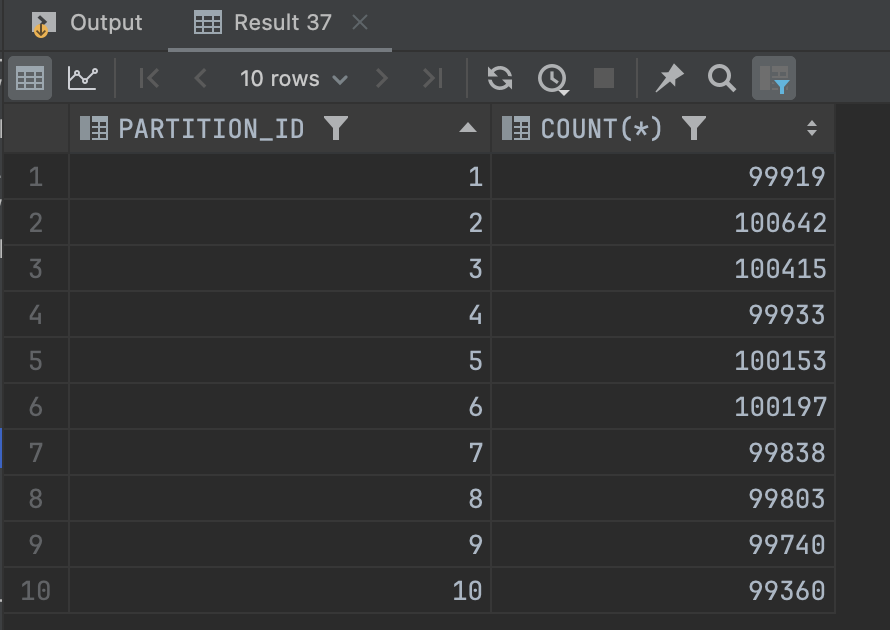
Sau đó mình kiểm tra lại việc phân bổ dữ liệu partition_id của các bản ghi account trên view mới, thấy rằng việc phân bổ này khá đồng đều.
Sửa lại chút logic thực hiện scan tài khoản từ materialized view mới
for (long i = 1; i <= 10; i++) {
long partitionId = i;
scanAccountByPartitionId(batchJobLog.getBatchUuid(), partitionId, dateTime);
}
public void scanAccountByPartitionId(String batchUuid, Long partition, LocalDateTime dateTime) {
var event = ScanAccountEvent.builder()
.batchUuid(batchUuid)
.partitionId(partition)
.time(dateTime)
.build();
eventPublisher.publishEvent(event,"queueSummary");
}Và sau khi tối ưu, thì thời gian scan danh sách account_view rơi vào khoảng là hơn 1 phút, tuy nhiên 1 phút này chỉ là thời gian scan danh sách tài khoản, còn việc tổng hợp dữ liệu của toàn bộ 4 step thì rơi vào khoảng 5 phút.
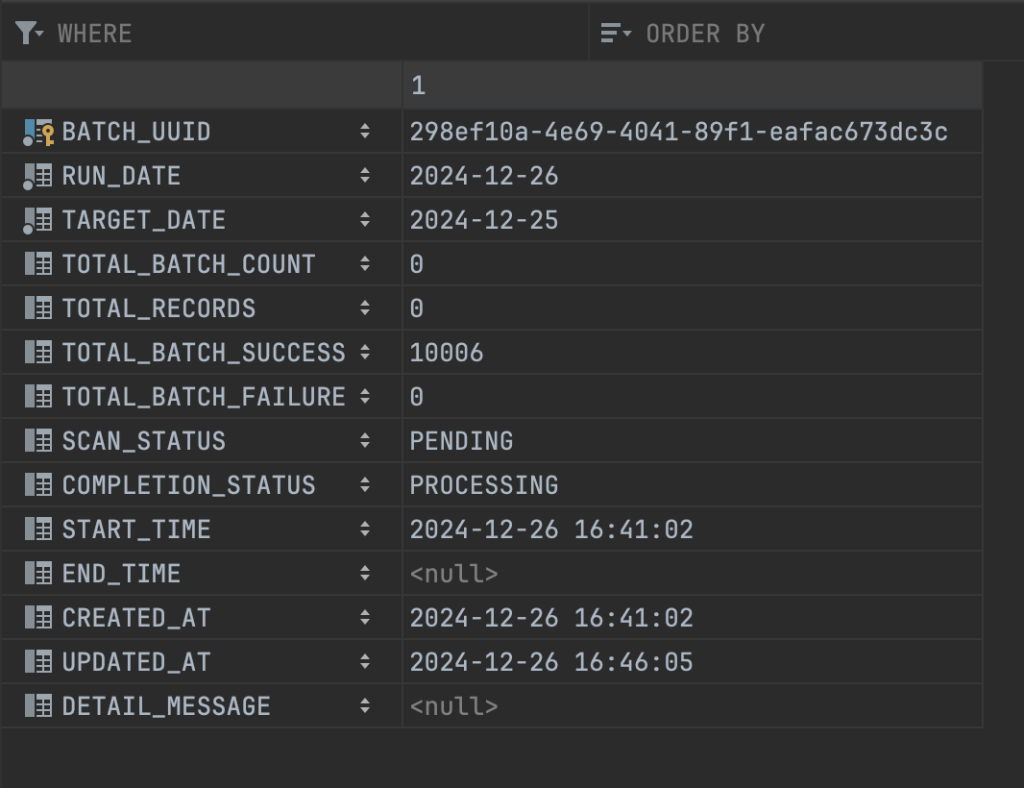
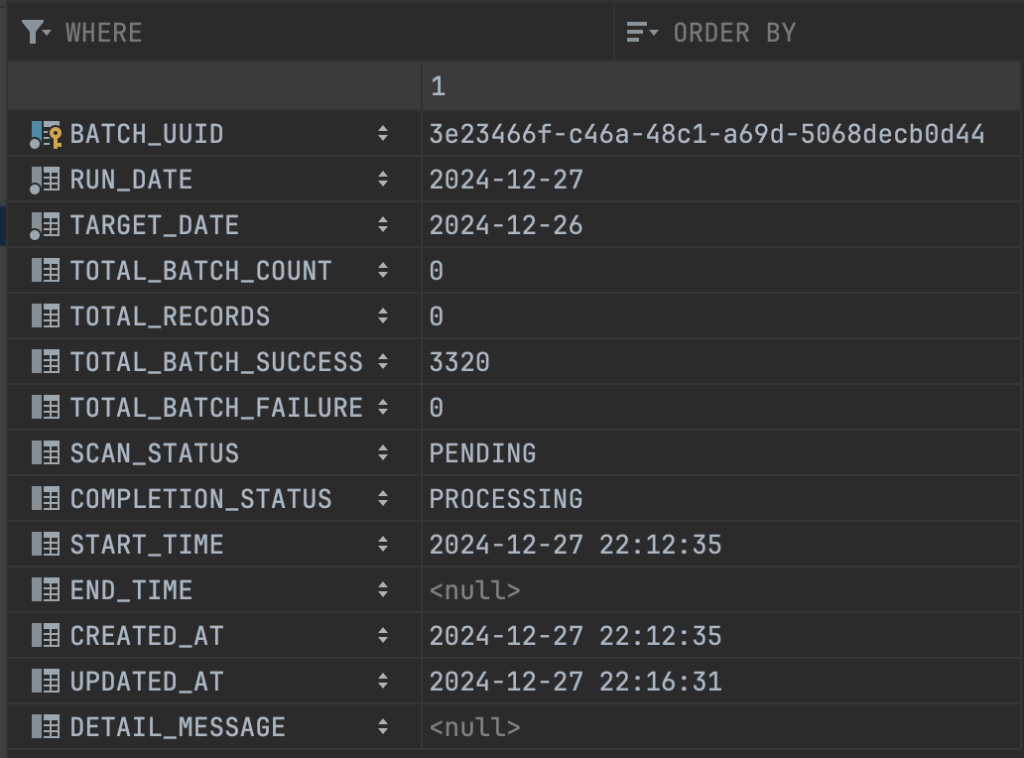
Số lượng batch đã xử lý thành công là 10006 batch, nhiều hơn một vài batch so với cách tiếp cận ban đầu là 6 batch, số lượng bản ghi tổng hợp cho 1 triệu tài khoản vào bảng summary đúng bằng 1 triệu tài khoản.
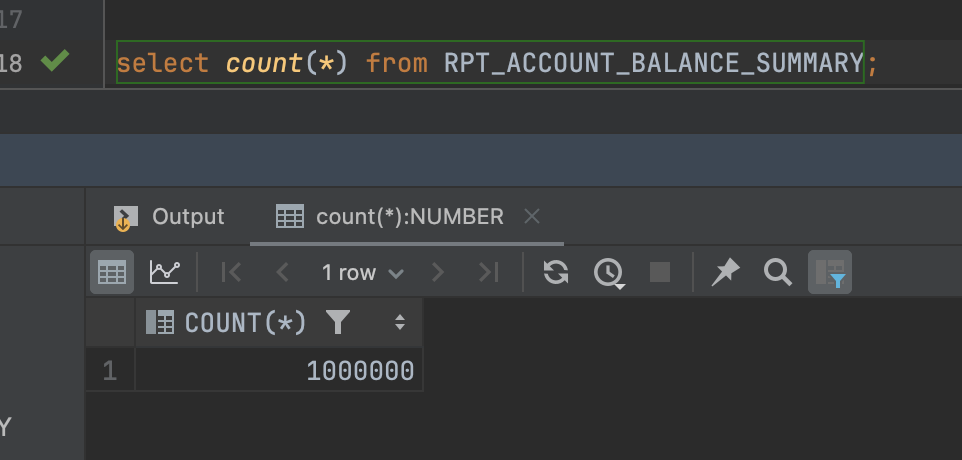
Giải thích lý do cho việc số batch đã xử lý thành công ở đây là 10006 batch, mà không phải 10000 batch, thì các bạn xem hình ảnh sau:
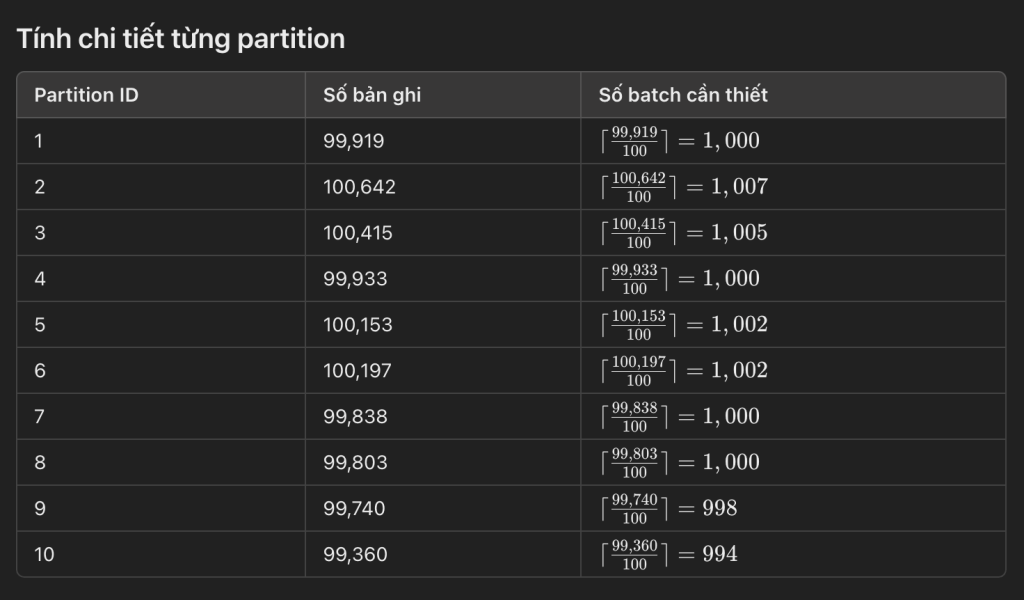
Chúng ta sẽ làm tròn lên để đảm bảo rằng tất cả các bản ghi được bao gồm đầy đủ trong các batch, kể cả nếu số bản ghi trong mỗi batch con không chia hết cho kích thước batch thì cũng cần tính.
Chúng ta có thể đánh giá sơ bộ được rằng là việc tối ưu bằng cách bổ sung thêm cột partition_id để chia nhiều luồng xử lý đã đem lại hiệu quả rất cao, tiết kiệm được khoảng 70% thời gian xử lý so với cách thông thường ban đầu.
Thay đổi kiến trúc bảng account từ đầu
Nếu trong những hệ thống cũ, hoặc việc triển khai các bảng biểu đã tồn tại rồi thì cách này gần như là bất khả thi và không thể nào thực hiện được.
Tuy nhiên mình giả sử mình được toàn quyền quyết định đến việc thay đổi kiến trúc bảng account ngay thời điểm đầu thì mình sẽ triển khai kiến trúc bảng theo các bước như sau:
- tạo thêm cột id sequence tự tăng trên bảng account ban đầu
- tạo thêm cột partition_id, cột này vẫn được hash dữ liệu dựa theo account_no, và đánh số từ 1 đến 10
- tạo 10 luồng xử lý cho 10 partition_id này, tuy nhiên sẽ thay đổi chút ở việc scan ở mỗi partition
- trên mỗi luồng, trong câu query để lấy ra dữ liệu account mình sẽ đánh dấu lại id của bản ghi cuối cùng, và dùng id đó để làm đầu vào cho câu query tiếp theo, như vậy mình sẽ tránh được việc phải quét toàn bảng so với những cách trước đó.
Oke giờ bắt tay vào tạo bảng mới và xử lý logic thôi:
Tạo bảng account mới
Bảng account mới sẽ có 4 trường dữ liệu: id, account_no, accounting_type, partition_id
create table ACCOUNT_NEW
(
ID NUMBER not null primary key,
ACCOUNT_NO VARCHAR2(50) not NULL UNIQUE,
ACCOUNTING_TYPE VARCHAR2(10),
PARTITION_ID NUMBER
);
create sequence ACCOUNT_NEW_SEQ start with 1 increment by 1;
create index ACCOUNT_NEW_PARTITION_ID_INDEX on ACCOUNT_NEW (PARTITION_ID);
Tạo package random dữ liệu bảng account_new
CREATE OR REPLACE PACKAGE PKG_ACCOUNT_NEW_UTIL AS
PROCEDURE INSERT_FAKE_DATA(p_num_records IN NUMBER);
END PKG_ACCOUNT_NEW_UTIL;
CREATE OR REPLACE PACKAGE BODY PKG_ACCOUNT_NEW_UTIL AS
PROCEDURE INSERT_FAKE_DATA(p_num_records IN NUMBER) IS
v_account_no VARCHAR2(255);
v_accounting_type VARCHAR2(255);
v_inserted_count NUMBER := 0;
BEGIN
WHILE v_inserted_count < p_num_records LOOP
v_account_no := '08' || TO_CHAR(DBMS_RANDOM.VALUE(1000000000, 9999999999), 'FM9999999990');
v_accounting_type := CASE WHEN DBMS_RANDOM.VALUE(0, 1) < 0.5 THEN 'DR' ELSE 'CR' END;
BEGIN
INSERT INTO ACCOUNT_NEW (ID, ACCOUNT_NO, ACCOUNTING_TYPE, PARTITION_ID)
VALUES (ACCOUNT_NEW_SEQ.nextval ,v_account_no, v_accounting_type, MOD(ORA_HASH(v_account_no), 10) + 1);
v_inserted_count := v_inserted_count + 1;
EXCEPTION
WHEN DUP_VAL_ON_INDEX THEN
NULL;
END;
END LOOP;
COMMIT;
END INSERT_FAKE_DATA;
END PKG_ACCOUNT_NEW_UTIL;BEGIN
PKG_ACCOUNT_NEW_UTIL.INSERT_FAKE_DATA(1000000);
END;
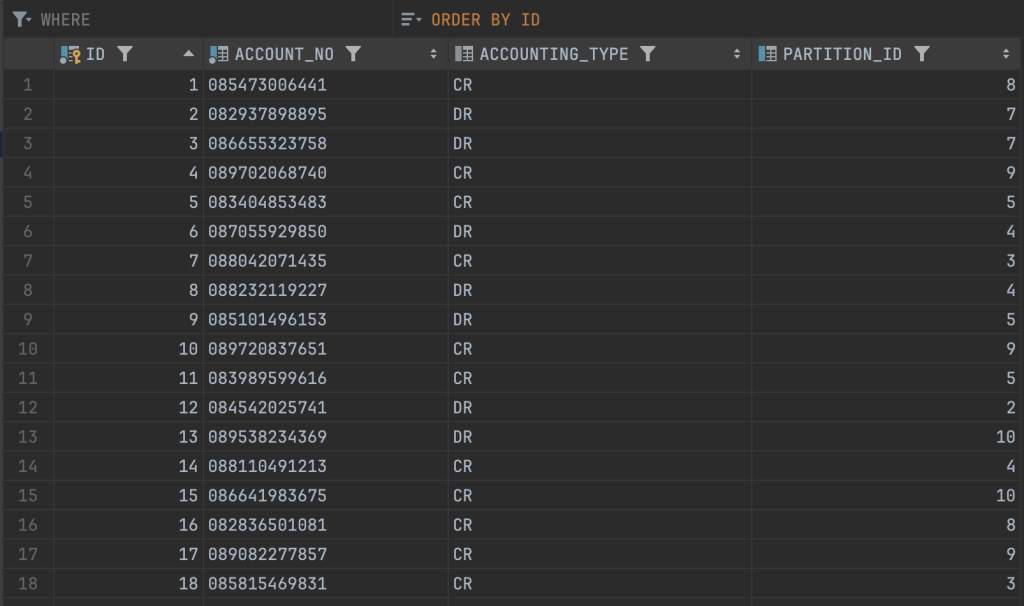
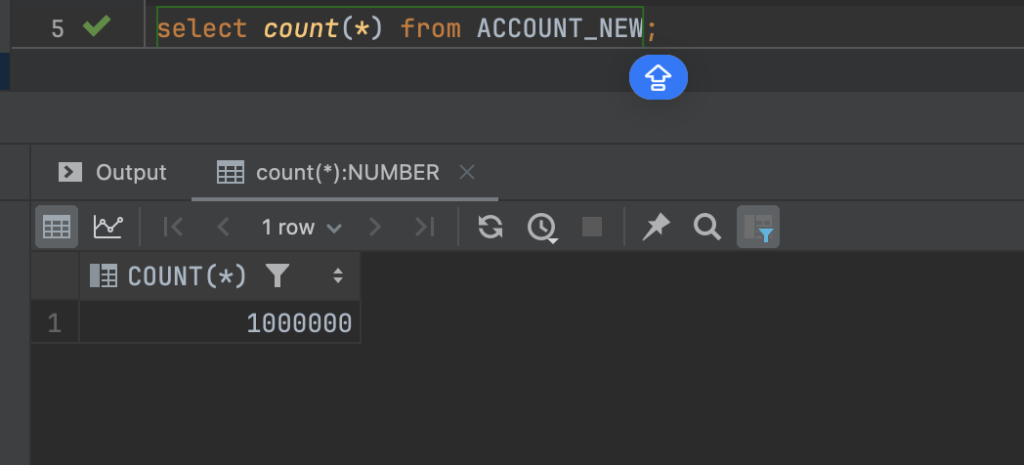
Dữ liệu account chúng ta đã chuẩn bị xong, giờ kiểm tra lại chút về việc phân bổ dữ liệu vào các partition.
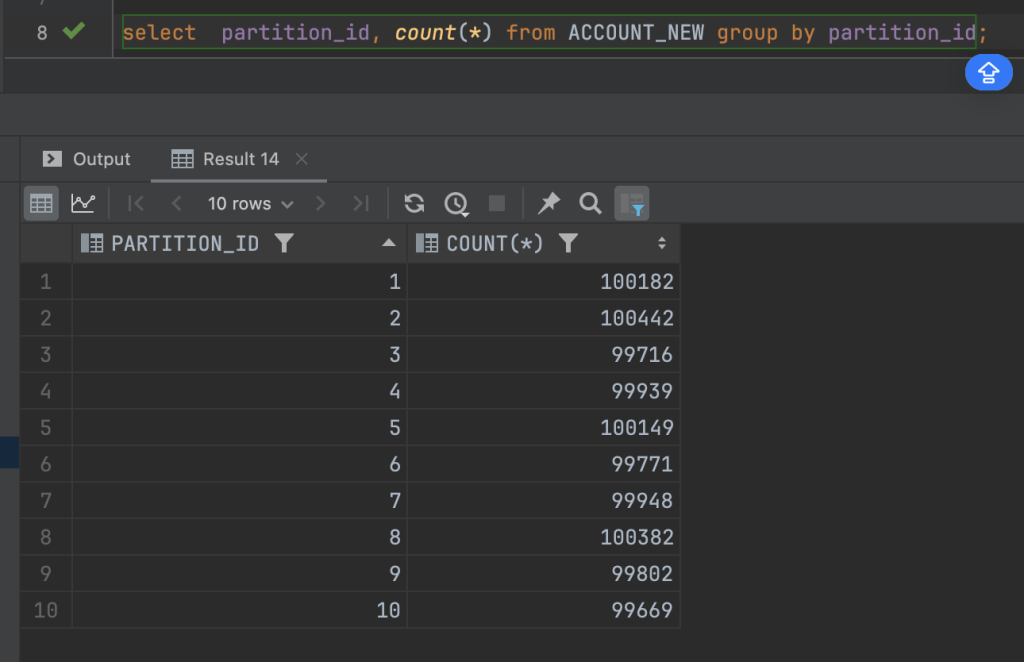
Xử lý lại logic việc đọc query
Oke giờ mới đến bước quan trọng, bước này chúng ta sẽ quét theo trường id của bảng, kèm theo partition_id
SELECT id, account_no, accounting_type, partition_id
FROM ACCOUNT_NEW where (id between FIRST_ID AND NEXT_ID ) and partition_id = PARTITION_ID order by id asc;FIRST_ID: là giá trị chạy tuần tự từ 0, sau mỗi lần chạy thì sẽ được thay đổi bằng id của bản ghi cuối cùng+1, ví dụ lần chạy thứ 2 sẽ lấy FIRST_ID bằng với id của bản ghi cuối cùng của lần chạy đầu tiên cộng thêm 1, cứ lặp lại như thế
NEXT_ID: giá trị này sẽ bằng FIRST_ID mới + khoảng chia batch của chúng ta, ví dụ từ đầu bài đến giờ mình chia batch là khoảng 100 phần tử, thì next_id sẽ bằng FIRST_ID + 100
PARTITION_ID: là giá trị từ 1-10 mà chúng ta đã phân nhóm tài khoản
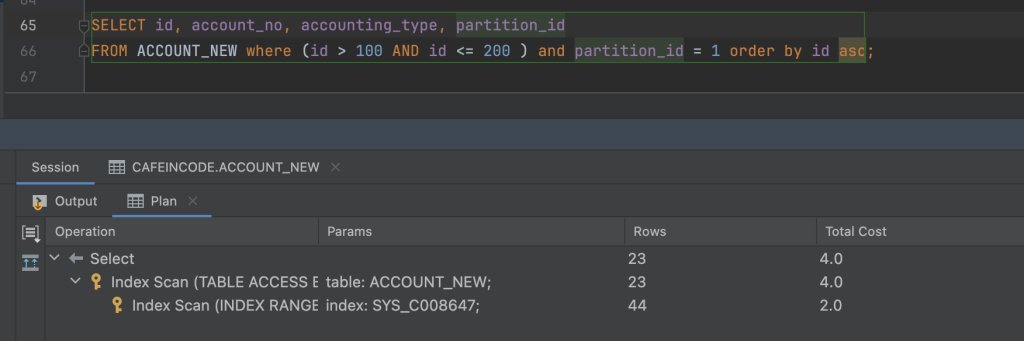
Hiệu suất câu truy vấn ổn, có sử dụng index, có thể quẩy thoải mái.
Chú ý quan trọng
Trong quá trình scan các bạn cần để ý điều sau, nếu chúng ta dùng điều kiện là danh sách kết quả không trống hoặc là chạy tới bản ghi cuối cùng của bảng thì sẽ không được tối ưu và sai sót.
Ở đây mình sẽ lấy ra id của bản ghi lớn nhất theo từng partition, sau đó sẽ cache lại và dùng nó để làm điều kiện dừng cho việc chạy query scan tài khoản ở trên.
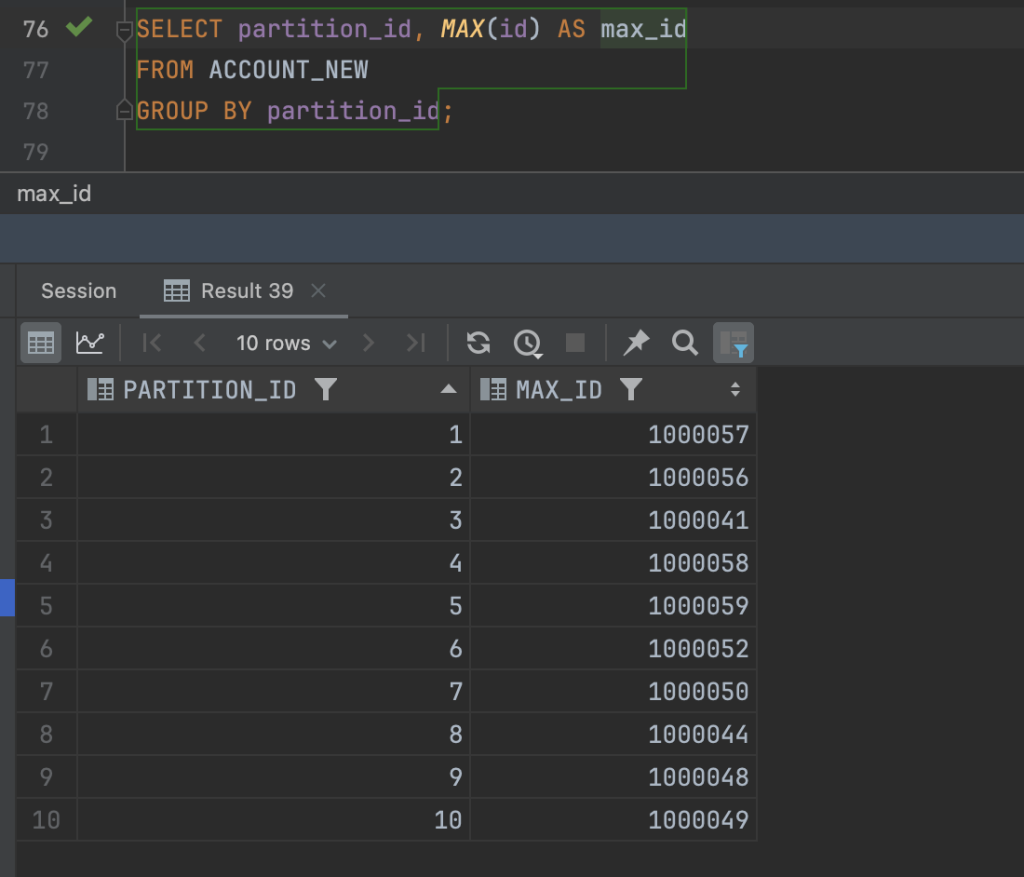
Logic xử lý scan tài khoản sẽ na ná như bên dưới:
var partitionId = event.getPartitionId();
long maxIdOfPartition = event.getMaxIdOfPartition();
long firstCursorId = 0;
long nextCursorId = firstCursorId + 1000;
int countingBatch = 0;
List<JpaAccount> accumulatedAccounts = new ArrayList<>();
try {
while (firstCursorId <= maxIdOfPartition) {
var accounts = accountRepository.findAccountsByCursor(firstCursorId, nextCursorId, partitionId);
if (!accounts.isEmpty()) {
accumulatedAccounts.addAll(accounts);
if (accumulatedAccounts.size() >= 100) {
var viewAccounts = mappingAccounts(accumulatedAccounts);
publishEvent(viewAccounts, batchUuid, countingBatch + 1, dateTime);
accumulatedAccounts.clear();
countingBatch++;
}
var lastCursorId = accounts.get(accounts.size() - 1).getId();
firstCursorId = lastCursorId + 1;
nextCursorId = firstCursorId + 1000;
}
}
if (!accumulatedAccounts.isEmpty()) {
var viewAccounts = mappingAccounts(accumulatedAccounts);
publishEvent(viewAccounts, batchUuid, countingBatch + 1, dateTime);
}
} catch (Exception ex) {
log.error("Error occurred during scan accounts: {}", ex.getMessage(), ex);
}Chạy project và đo đạc kết quả
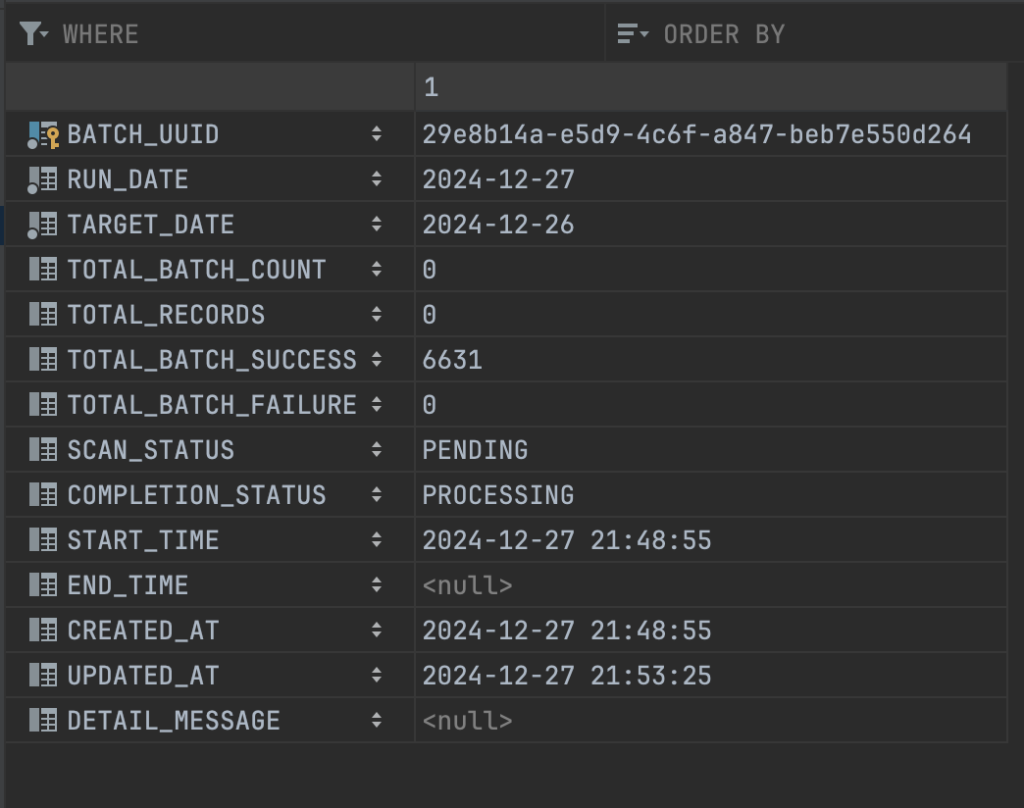
Tổng thời gian xử lý scan bảng account_new và xử lý tổng hợp dữ liệu, lưu xuống database, cập nhật biến đếm số lượng batch đã xử lý rơi vào khoảng hơn 4 phút
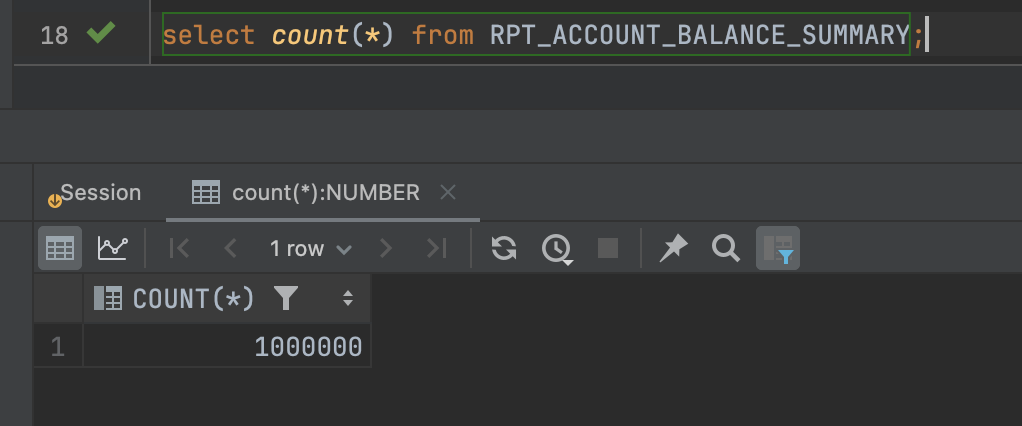
Tổng số lượng account đã scan là 1 triệu, và đây là bảng dữ liệu tổng hợp cuối, con số cũng là 1 triệu bản ghi.
Giờ trong đoạn code xử lý scan mình sẽ thực hiện thay đổi tham số batchSize từ 1000 lên 2000, và từ 100 lên 200 để xem liệu sự thay đổi này có đem lại hiệu quả không nhé.
var partitionId = event.getPartitionId();
long maxIdOfPartition = event.getMaxIdOfPartition();
long firstCursorId = 0;
long nextCursorId = firstCursorId + 2000;
int countingBatch = 0;
List<JpaAccount> accumulatedAccounts = new ArrayList<>();
try {
while (firstCursorId <= maxIdOfPartition) {
var accounts = accountRepository.findAccountsByCursor(firstCursorId, nextCursorId, partitionId);
if (!accounts.isEmpty()) {
accumulatedAccounts.addAll(accounts);
if (accumulatedAccounts.size() >= 200) {
var viewAccounts = mappingAccounts(accumulatedAccounts);
publishEvent(viewAccounts, batchUuid, countingBatch + 1, dateTime);
accumulatedAccounts.clear();
countingBatch++;
}
var lastCursorId = accounts.get(accounts.size() - 1).getId();
firstCursorId = lastCursorId + 1;
nextCursorId = firstCursorId + 2000;
}
}
if (!accumulatedAccounts.isEmpty()) {
var viewAccounts = mappingAccounts(accumulatedAccounts);
publishEvent(viewAccounts, batchUuid, countingBatch + 1, dateTime);
}
} catch (Exception ex) {
log.error("Error occurred during scan accounts: {}", ex.getMessage(), ex);
}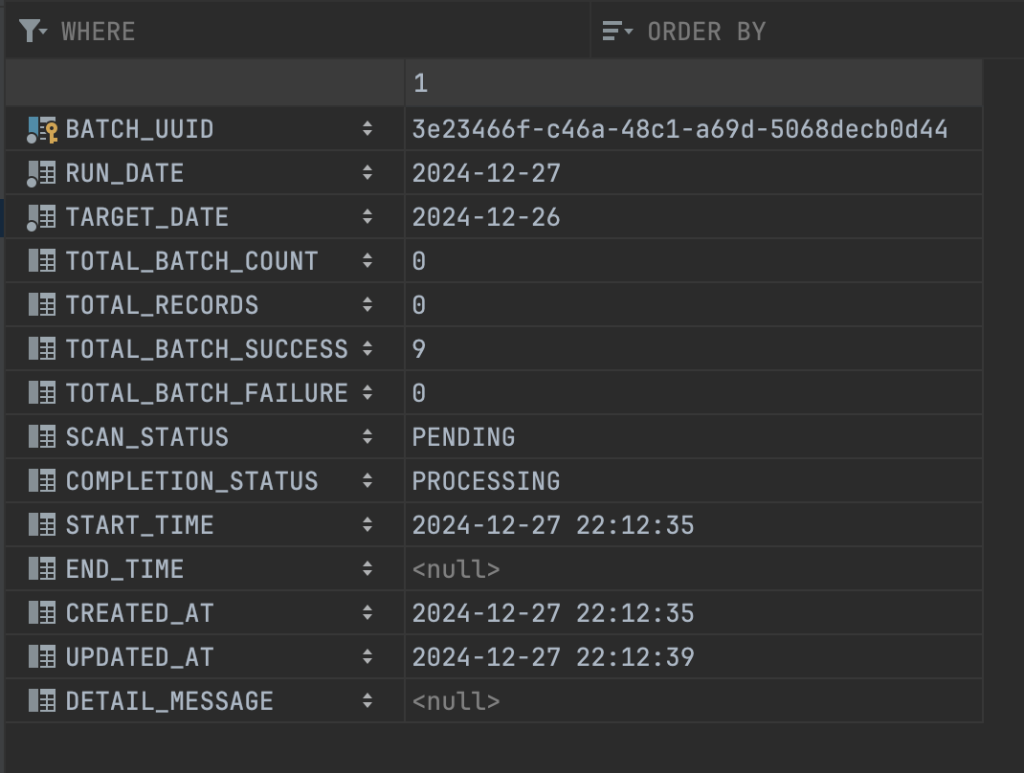
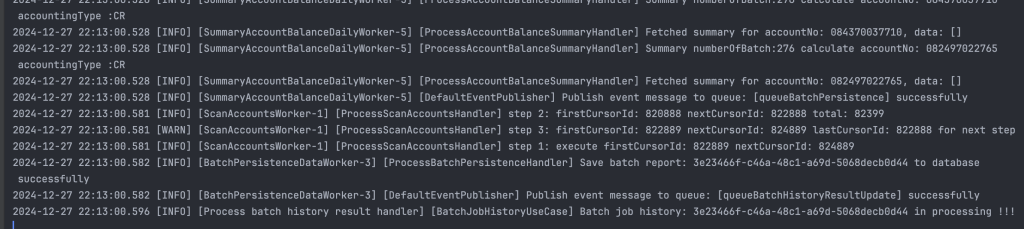
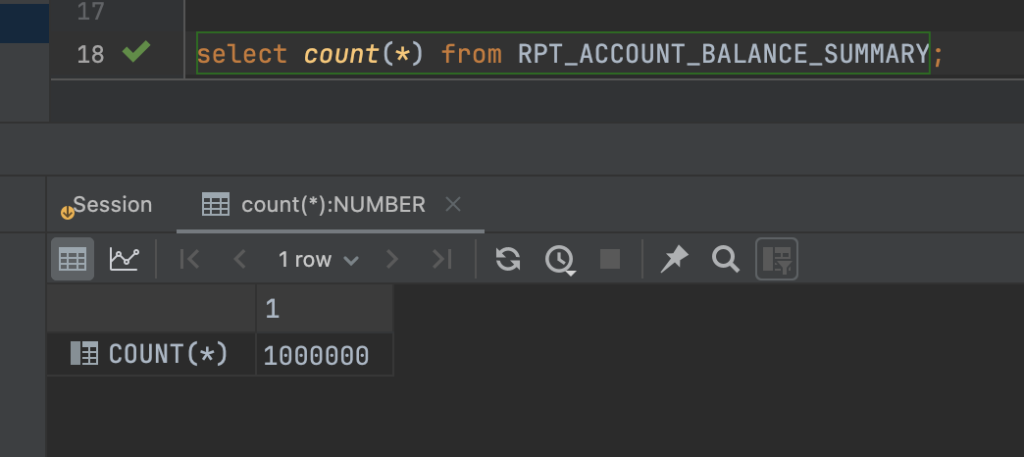
Tổng thời gian thực hiện là tròn 4 phút, tuy nhiên mình có thể tối ưu thêm về mặt flow xử lý và tối ưu thời gian ở step 2, step 3 và step 4 thêm như sau:
- hiện tại mình đang dùng queue inmemory và chia luồng thủ công nên sẽ chỉ tối ưu khi chạy trên 1 instance, các bạn có thể tối ưu thêm bằng việc dùng Hazelcast để phân tải xử lý trên nhiều instance
- Chưa có xử lý retry khi lưu batch bị lỗi
- Chưa có phần monitor job
Bài viết đã hơi dài rồi, mình xin tạm dừng việc điều chỉnh lại và sẽ tối ưu ở những bài viết sau này, ở bài viết sau mình sẽ thử chạy job trên tập data khoảng 15-20 triệu xem tổng thời gian xử lý là hết bao nhiêu phút, các bạn chú ý đón xem nhé.
Hiện tại mình có đẩy các bài viết lên trên Medium và Substack, các bạn quan tâm có thể chia sẻ cho bạn bè, nhấn follow, subscriber hoặc đơn giản chỉ cần bấm thả tim, vỗ tay thôi là mình có động lực viết những bài viết mới rồi, mình xin cảm ơn.
Xem thêm các bài viết nổi bật ở bên dưới:
- Những thói quen tốt trong ngành phát triển phần mềm
- Tôi đã hoàn thành cự ly Half Marathon Long Biên 2024
- Lần đầu chinh phục thành công Half Marathon
- Phỏng vấn dạo kĩ sư phần mềm 2023
- Git flow ở công ty nghìn người sẽ như thế nào
- Viết code với những thói quen tốt này sẽ giúp bạn giỏi hơn
- Kĩ năng quản lý căng thẳng cho Developer
- Làm việc trong môi trường Agile là như thế nào
- Là kĩ sư phần mềm hãy cố gắng giữ gìn sức khỏe bản thân
- Bạn không giỏi lắng nghe như bạn nghĩ đâu
- Git stash giúp bạn trở nên chuyên nghiệp như thế nào?
- How to build Cron Job for multiple instances with Shedlock
- Rest API: Cách Ngăn Chặn Duplicate Request Hiệu Quả