
Elasticsearch là một công cụ tìm kiếm dựa trên thư viện Lucene, là phần mềm miễn phí, mã nguồn mở xây dựng bằng ngôn ngữ Java. Elasticsearch đã trở thành công cụ tìm kiếm (search engine) thông dụng nhất và được sử dụng rộng rãi cho các công việc liên quan đến chỉ mục và tìm kiếm tài liệu, phân tích dữ liệu …
Thay vì tìm kiếm dữ liệu trong một cơ sở dữ liệu thông thường như MySQL, Oracle,… thì ta chuyển dữ liệu đó vào Elasticsearch và tìm kiếm thông qua nó luôn, rất hiệu quả với dữ liệu lớn.
1. Cơ chế hoạt động
Elasticsearch hoạt động như một Cloud Server theo cơ chế RESTful, tức là từ Client tạo ra các HTTP Request (GET, PUT …) kèm dữ liệu dạng JSON để tương tác với Elasticsearch (POST, PUT, DELETE, GET,…).
Để tạo ra Http Request gửi đến Elasticsearch thì bạn có thể dùng các loại ngôn ngữ khác nhau để xây dựng hệ thống: Java, PHP, Ruby, .Net, Python,…
Tất cả dữ liệu được lưu vào Elasticsearch đều được đánh Index(chỉ mục), vì thế hiệu năng tìm kiếm của Elasticsearch rất cao.
2. Một số khái niệm cần biết
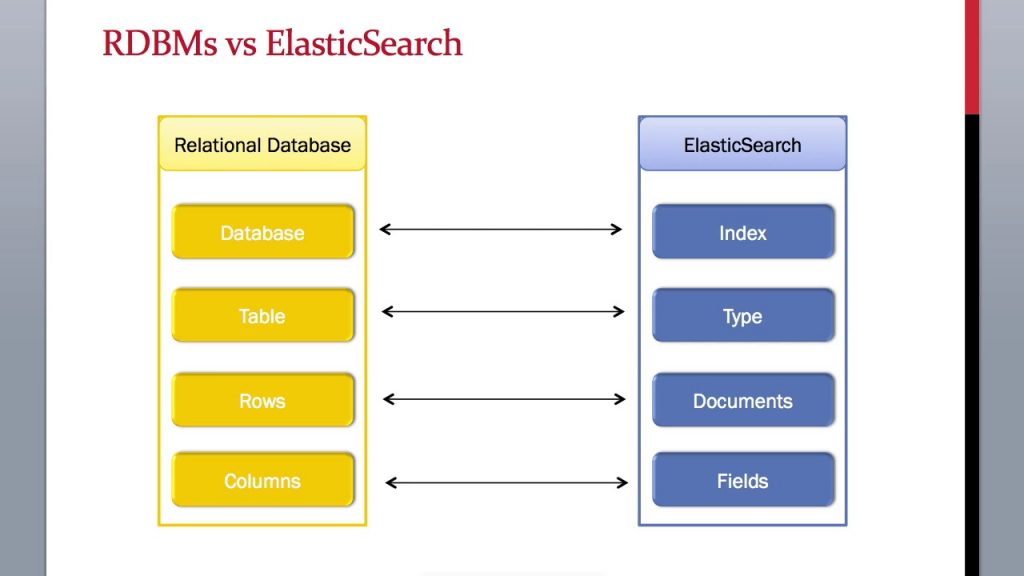
Cluster: Là một tập hợp các Node (các server) chứa tất cả các dữ liệu. Mỗi cluster được định danh bằng một unique name, mỗi cluster có một node chính (master) được lựa chọn tự động và có thể thay thế.Node: Một server duy nhất chứa một số lượng dữ liệu nhất định, tham gia đánh chỉ mục cho cluster và thực hiện tìm kiếm, mỗi node được định danh bằng một unique name.Index: Index ở đây không phải là chỉ mục như một số cơ sở dữ liệu thông thường, nó là một tập hợp các documents. Thường mỗi index là một loại dữ liệu nào đó của bạn ví dụ như index các sản phẩm, index chứa các đơn hàng, index chứa các bài viết …. Mỗi index được định danh bằng một tên (chữ thường), tên này sẽ phục vụ việc đánh chỉ mục và tìm kiếm, cập nhật dữ liệu của document trong nó. Hiểu đơn giản nó như khái niệm databases trong mysql.Type: Là một tập hợp các documents cùng loại, tương tự khái niệm table trong mysql.Document: được coi như đơn vị nhỏ nhất của Elasticsearch, nó là một JSON Obj chứa một số trường dữ liệu nhất định. Mỗi document giống như mỗi row trong mysql.Shards: Tập hợp con các document của một Index, mỗi shards có thể coi là một index có thể trực tiếp giúp tính toán, tìm kiếm song song.
3. Ưu điểm
- Tìm kiếm dữ liệu rất nhanh chóng, gần như là realtime (hay còn gọi là near-realtime searching).
- Tìm kiếm theo nhiều loại hình thức khác nhau: tìm kiếm theo dạng text thông thường, query like, dạng dữ liệu có cấu trúc,
- Phục vụ việc tổng hợp dữ liệu mạnh mẽ.
4. Nhược điểm
- Elasticsearch được thiết kế chuyên biệt để tìm kiếm, vậy nên những chức năng khác như CRUD thì elasticsearch kém hơn những loại databases khác. Chính vì thế không nên sử dụng Elasticsearch làm database chính.
- Do hỗ trợ nhiều loại Elasticsearch client khác nhau, không cung cấp tính năng hay phân quyền nào cho việc xác thực, nên elasticseach kém bảo mật hơn các loại cơ sở dữ liệu quan hệ hiện tại.
- Không có khái niệm database transaction nên sẽ không bảo toàn tính toàn vẹn của dữ liệu, không thích hợp cho những hệ thống cập nhật dữ liệu nhiều.
Done, bài sau mình sẽ hướng dẫn các bạn dựng Elasticsearch bằng Docker Compose, và cách sử dụng.
Một số bài viết liên quan:
- Tìm hiểu cơ chế hoạt động của Apache Kafka [Phần 1]
- Series tìm hiểu lập trình java
- Cùng nhau tìm hiểu Docker
- Build hệ thống Pub Sub dùng Hazelcast và Spring boot
- Elasticsearch và Kibana dựng bằng Docker
- Active Jrebel để code trong IntellIJ IDEA
- Câu chuyện phỏng vấn online mùa Covid
- Lập trình viên lúc rảnh rỗi thì nên làm gì?